
대분류/20
정보통신
중분류/01
정보기술
소분류/02
정보기술개발
세분류/04
DB엔지니어링
능력단위/04
NCS학습모듈
물리 데이터베이스
설계
LM2001020404_16v3

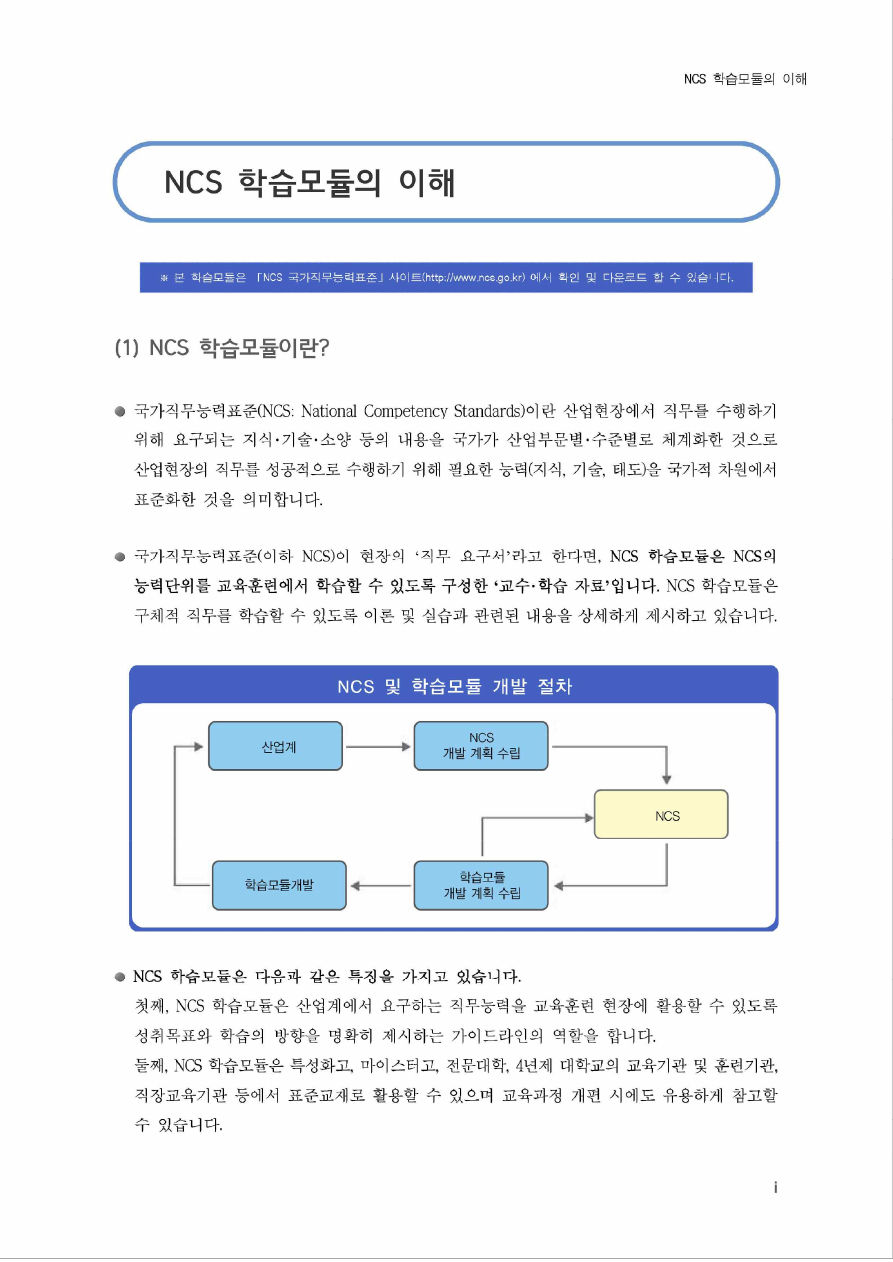






[NCS-학습모듈의 위치]
대분류
정보통신
중분류
정보기술
소분류
정보기술개발
세분류
SW아키텍쳐
능력단위
학습모듈명
응용SW
엔지니어링
데이터베이스 요구사항 분석
데이터베이스 요구사항 분석
임베디드SW
엔지니어링
개념데이터 모델링
개념데이터 모델링
DB엔지니어링
논리 데이터베이스 설계
논리 데이터베이스 설계
NW엔지니어링
물리 데이터베이스 설계
물리 데이터베이스 설계
보안엔지니어링
데이터베이스 구현
데이터베이스 구현
데이터 품질관리
데이터 품질관리
UI/UX엔지니어링
데이터 전환 설계
데이터 전환 설계
시스템SW
엔지니어링
데이터 전환
데이터 전환
데이터베이스 성능확보
데이터베이스 성능확보
데이터 표준화
데이터 표준화
SQL활용
SQL활용
SQL응용
SQL응용

차 례
학습모듈의 개요
1
학습 1. 물리 속성 조사 분석하기
1-1. 시스템의 조사 및 분석
3
• 교수・학습 방법
11
• 평가
12
학습 2. 데이터베이스 물리 속성 설계하기
2-1. 데이터베이스 물리 속성 설계
14
2-2. 물리 데이터베이스 설계서 작성
23
• 교수・학습 방법
45
• 평가
46
학습 3. 물리 E-R 다이어그램 작성하기
3-1. 물리 ERD의 변환과 작성
48
• 교수・학습 방법
58
• 평가
59
학습 4. 데이터베이스 반정규화하기
4-1. 반정규화 수행
61
• 교수・학습 방법
68
• 평가
69
학습 5. 물리 데이터 모델 품질 검토하기
5-1. 물리 데이터 모델 품질 점검
71
• 교수・학습 방법
78
• 평가
79
참고 자료
81

1
물리 데이터베이스 설계 학습모듈의 개요
학습모듈의 목표
논리 데이터베이스 구조(스키마), 처리 요구 조건, 데이터베이스, 하드웨어, 운영 체제 특성을
기반으로 물리 데이터베이스 저장 형식의 분석, 설계, 접근 경로를 물리적으로 설계할 수 있다.
선수학습
논리 데이터베이스 설계 (2001020403_14v2), 데이터 표준화 (2001020409_14v2), 데이터 품질 관
리(2001020406_14v2)
학습모듈의 내용체계
학습
학습 내용
NCS 능력단위요소
코드번호
요소명칭
1. 물리 속성 조사
분석하기
1-1. 시스템의 조사 및 분석
2001020404_16v3.1
물리 속성 조사
분석하기
2. 데이터베이스
물리 속성
설계하기
2-1. 데이터베이스 물리 속성 설계
2001020404_16v3.2
데이터베이스 물리
속성 설계하기
2-2. 물리 데이터베이스 설계서 작성
3. 물리 E-R
다이어그램
작성하기
3-1. 물리 ERD의 변환과 작성
2001020404_16v3.3
물리 E-R 다이어그램
작성하기
4. 데이터베이스
반정규화하기
4-1. 반정규화 수행
2001020404_16v3.4
데이터베이스
반정규화하기
5. 물리 데이터
모델 품질
검토하기
5-1. 물리 데이터 모델품질 점검
2001020404_16v3.5
물리 데이터 모델 품질
검토하기
핵심 용어
도메인, 데이터 용어 사전, 시스템 자원, 하드웨어 자원, 데이터베이스 관리 요소, 데이터베이스
구조, 테이블(Table), 테이블스페이스(Table space), 칼럼(Column), 파티션(Partition), 뷰

3
학습 1 물리 속성 조사 분석하기
학습 2
데이터베이스 물리 속성 설계하기
학습 3
물리 E-R 다이어그램 작성하기
학습 4
데이터베이스 반정규화하기
학습 5
물리 데이터 모델 품질 검토하기
1-1. 시스템의 조사 및 분석
학습 목표
• 기존 시스템을 분석하여 업무 영역과 시스템 영역으로 구분하여 용어 사전 기반으로
명명 규칙을 파악할 수 있다.
• 서버, 네트워크, 스토리지 자원을 조사하고, 데이터베이스가 설치될 시스템의 운영체
계와 데이터베이스 버전을 확인할 수 있다.
• 데이터베이스 운영과 관련된 관리 요소를 파악하고, 데이터베이스 구조, 이중화 구
성, 분산 구조, 접근제어, DB 암호화에 대한 시스템 조사 분석서를 작성할 수 있다.
필요 지식 /
비즈니스 도메인과 명명 규칙
물리데이터 모델링을 위한 명명 규칙 파악을 위해 기존 시스템을 분석하고 업무 영역과
시스템 영역으로 구분하여 용어 사전을 기반으로 명명 규칙을 파악하기 위해서 도메인과
용어 사전에 대한 지식이 필요하다.
1. 데이터 명명 규칙
조직 내 시스템 구축과 관련된 명명 규칙을 의미하며, 물리 데이터 모델 각각의 요소의
내용에 이를 적용해야하므로 데이터 명명 규칙의 파악이 필요하다.
시스템의 데이터 명명 규칙은 데이터 용어 사전을 통해 파악할 수 있으며, 데이터 명명
규칙 파악을 통해 물리 데이터베이스 설계 시 발생할 수 있는 중복 구축 등의 혼란을 방
지하고, 논리적 데이터 요소의 물리적 전환 시 동일 명칭 부여의 근거로 활용할 수 있다.
2. 도메인
모델링에서 도메인은 객체(엔티티: Entity) 타입의 속성에 대한 데이터 타입과 크기, 제약
을 지정하는 것이다. 데이터베이스의 설치 시 칼럼 정보로 보이는 정보를 데이터 모델링
단계에서 공통된 표준화 규칙에 따라 정의하는 것을 도메인 정의라고 한다.

4
3. 데이터 용어 사전
데이터 용어 사전(데이터 사전)이란 데이터 속성명의 논리적 명칭과 물리적 명칭을 업무
에 적합하고 전체 프로젝트 및 전사 시스템에 일관성 있는 데이터 이름과 인터페이스를
제공하기 위해 논리명(Logical Name), 물리명(Physical Name), 용어 정의(Definition)을 기술
해 놓은 것이다.
데이터 용어 사전은 논리 데이터 모델의 속성과 테이블에 업무적인 용어를 적용하고, 프
로젝트에서 사용하는 명칭을 부여하는 근거로 사용하여 데이터 모델과 애플리케이션 인터
페이스에서 효율적인 정보 시스템을 구축하는데 사용된다.
시스템 운영 체계 및 자원
시스템 운영 체계 및 자원은 데이터베이스 설치에 영향을 미칠 수 있어 파악이 필요한 물
리적 요소를 말하며, 대표적으로 하드웨어 자원, 운영체제 및 DBMS 버전, DBMS 파라미터
정보 등으로 나뉜다.
1. 하드웨어 자원
대표적인 하드웨어 자원에는 크게 중앙처리장치 (CPU: Central Processing Unit), Memory,
DISK, I/O Controller, Network 등에 대한 자원 정보가 있다.
첫째, 중앙처리장치(CPU: Central Processing Unit)관련 자원 정보는 장치의 성능과 장치의
활용과다로 인한 부하가 집중되는 시간 등의 정보가 포함된다.
둘째, 메모리(Memory) 자원 관련 정보는 시스템의 전체 메모리 규모 등 확보된 자원에 대
한 정보와 시스템이 사용하는 메모리 영역 및 사용 가능한 메모리 영역 등에 대한 실질적
인 시스템 활용 정보 등이 포함된다.
셋째, 디스크 (DISK) 자원 관련 정보는 메모리와 유사한 전체 디스크의 크기 등의 확보된
디스크 자원에 대한 정보와 분할된 형태, 현재 디스크 활용률 등의 정보와 사용 가능한
디스크 공간 등 시스템의 디스크 활용 관련 정보 등이 포함된다.
넷째, I/O Controller 자원 관련 정보는 현행 시스템의 입/출력 컨트롤러 성능에 대한 정보
를 비롯 운용의 적절성 등의 정보가 포함된다.
다섯째, 네트워크 (Network) 자원 관련 정보는 시스템 네트워크의 현행 처리가능 정도와
제공 가능 처리속도, 네트워크 부하의 주 발생시간, 동시 접속 가용 정도에 대한 정보 등
이 포함된다.
2. 운영체제 및 DBMS 버전
운영체제와 DBMS 버전의 차이는 운영 환경에 영향을 미칠 수 있다. 따라서 운영 환경과
관련된 운영체제의 관련 요소를 파악하고 적절하게 관리되고 있는가를 파악하며, 특히 인

5
스턴스 관리 기법 등에 대해서 파악 및 분석하기 위해 운영체제와 DBMS 버전에 대한 확
인이 필요하다.
3. DBMS 파라미터(Parameter) 정보 파악
DBMS 파라미터는 데이터베이스 관리 시스템별로 많은 차이가 있으며 관리하는 방법도
서로 다르다. 따라서 시스템별로 다른 자신들의 DBMS의 파라미터 종류 및 관리 대상 등에
대한 정확한 파악과 정의가 필요하다. 특히 DBMS를 위한 저장 공간, 메모리 등에 대한 관
리 기법에 관한 파라미터들의 파악에 대해서는 세심한 주의가 필요하다. 또한 쿼리에서 활
용하는 옵티마이져(Optimizer)의 사용 방법 등의 파악도 매우 주요한 고려 사항이다.
(1) 파라미터(Parameter)
실행 환경과 프로그램 간의 값을 주고받는 역할을 하는 것으로 블록 내에서 변수와
동일하게 일시적으로 값을 저장하는 역할을 한다.
묵시적 파라미터: 지정하지 않을 경우 자동으로 기본 값을 갖는다.
명시적 파라미터: 지정해야만 값을 갖는다.
4. 데이터베이스 특성, 스토리지 종류와 제원, 서버, 네트워크 특성 파악의 필요성
시스템 운영 체계 및 자원의 내용을 파악하기 위해 시스템 구성 요소인 데이터베이스와
서버, 네트워크, 스토리지, 운영체제 등에 대한 제원을 파악해야 한다. 기존에 작성되어
관리되어온 내역이 있다면 확인 후 참조할 수 있으나, 그렇지 않다면 각각의 제원 상의
내용은 출시 시점 또는 버전에 따라 달라질 수 있으므로 제품 매뉴얼이나 관련 사이트에
서 정확히 확인할 필요가 있다.
데이터베이스 관리 요소
데이터베이스 관리 요소는 데이터베이스 운영과 관련된 관리 요소로 사용자 관리 기법 및
정책, 백업/복구 기법 및 정책, 보안 관리 정책 등이 포함된다. 이러한 데이터베이스 관리
요소를 기반으로 원활한 운영을 방해하는 물리적 사고, 데이터 유출, 장애나 에러의 발생
등에서 데이터베이스 운영을 보장하기 위해 필요한 데이터베이스 구조, 이중화 구성, 분산
구조, 접근제어, DB암호화 등의 범위와 특성을 파악할 수 있다.
데이터베이스 관리 요소는 주로 데이터베이스의 보안 관리의 내용으로 구성된다. 따라서 관련
지식은 ‘DB 엔지니어링’의 ‘데이터 품질 관리 (2001020406_14v2)’의 내용을 참조한다.
1. 데이터베이스 구조
데이터베이스별로 구조에는 차이가 있으며, 차이에 따라 사용중 발생하는 문제에 대한 대
응 방법이 다르게 나타날 수 있다. 데이터의 안전한 저장과 관리를 위해서 서버와 데이터
베이스의 구조에 대한 이해가 필요하다.

6
2. 이중화 구성
장애발생시 데이터베이스를 보호하기 위한 방법으로 동일한 데이터베이스를 중복시켜 동
시에 갱신하여 관리하는 방법이다. 데이터베이스의 종류나 구현 방향에 따라 활용 방법에
차이가 있을 수 있다.
3. 분산구조 (분산 데이터베이스)
네트워크의 활용을 통해 단일한 데이터베이스 관리 시스템으로 제어되고 논리적으로 집중
되어 있으나 물리적으로 분산되어 있는 분산 데이터베이스의 형태를 띄는 경우가 있다.
데이터베이스의 복제 및 분산을 통해 사용자 측면에서는 향상된 성능을 제공하는 장점 뿐
아니라, 물리적 재해 및 파손 등에서 데이터의 유실을 최소화할 수 있고, 장애로 인한 데
이터 유실 복구에도 효과적이므로 분산구조에 대한 파악이 필요하다.
4. 접근제어
데이터베이스는 DMZ를 거쳐 조직의 가장 내부에 위치하고 있고 DBMS 자체가 강력한 보
안기능을 제공하기 때문에 해킹보다는 데이터베이스에 접근 권한을 가진 사용자가 권한을
남용하여 정보를 유출하거나 변조하는 것이 가장 중요한 위협이될 수 있다. 따라서 데이
터베이스의 구현과 안정적 관리를 유지하기 위해 접근제어에 대해 파악할 필요가 있다.
5. DB암호화
정보자원 특히 데이터에 대한 중요성이 높아지면서 데이터베이스 보호에 대한 중요성도 점차
증가하고 있다. 데이터베이스 보안에서 접근제어 외에 중요하게 다루는 분야가 DB암호화다.
DB암호화는 데이터 암호화와 암호 키에 대한 인증 및 권한 관리로 구성되며, 강력한 인증
및 권한 관리를 통해 데이터 유출이 발생해도 복호화를 어렵게 한다.
수행 내용 / 데이터 명명 규칙 파악하기
재료·자료
Ÿ
논리 데이터베이스 설계 산출물
Ÿ
표준 데이터(표준 용어 사전, 표준 단어 사전, 표준 도메인 사전, 표준 코드 사전)
Ÿ
시스템 구성 요소(데이터베이스, 서버, 네트워크, 스토리지, 운영체제 등) 제원
Ÿ
시스템 운영 모니터링 결과 / 시스템 사용자 현황 조사(인터뷰/설문) 결과

7
Ÿ
데이터 품질 관리의 데이터베이스 관리 정책 또는 데이터 보안 정책관련 자료(관리적/기술적
정책, 가이드라인, 지원도구, 절차 등)
기기(장비 ・ 공구)
Ÿ
컴퓨터, 프린터
Ÿ
문서 작성 도구
Ÿ
DBMS
안전 ・ 유의 사항
Ÿ
물리 데이터베이스 설계에서 적용되는 명명 규칙은 대부분 논리 데이터베이스 설계의 명명과
일관성을 유지해야 한다.
Ÿ
사용 중인 시스템이거나 출시된지 오랜 시간이 흐른 시스템의 구성 요소의 경우 발생할 수
있는 상황(제원 성능과 활용 성능이 다를 수 있는 경우)을 고려해야 한다.
Ÿ
상위 단계에서 작성된 데이터베이스 관리 및 보안 정책을 반드시 숙지하고 준수한다.
수행 순서
데이터를 명명한다.
1. 데이터 표준화 및 논리 데이터베이스 설계 결과 등을 통한 데이터 명명 규칙을 파
악한다.
(1) 확정된 표준 데이터(표준 용어 사전, 표준 단어 사전, 표준 도메인 사전, 표준 코
드 사전 등) 내용을 확인한다.
(2) 기존 시스템 분석을 통해 실제 데이터 명명 현황을 확인하고 표준 데이터의 적
용 여부와 명명 규칙을 파악한다.
(3) 논리 데이터베이스 설계에서 각각의 객체와 속성 등에 부여된 명칭을 확인한다.
(4) 논리 데이터베이스 설계의 데이터 명명 현황을 확인하고 데이터 표준화 자료와
기존 시스템 분석을 통해 파악된 명명 규칙의 적용여부를 파악한다.
2. 데이터 표준화 부재 및 기존 시스템의 데이터 명명 규칙이 미흡한 경우 처리하기
(1) 표준 데이터(표준 용어 사전, 표준 단어 사전, 표준 도메인 사전, 표준 코드 사전

8
등)의 기준이 수립되어 있지 않거나, 기존 시스템에 데이터 표준화 기준이 제대로
적용되어 있지 않은 경우, 표준 데이터 기준을 새롭게 개발하거나 보완해야 한다.
(2)‘데이터 표준화(2001020409_14v2)’학습 도구를 참조하여 업무와 시스템의 특성
이 반영된 표준 데이터의 기준을 수립한다.
(3) 논리 데이터베이스 설계에 명명된 데이터 요소들에 대한 검토를 통해 표준 데이
터의 기준을 반영하여 논리와 물리 데이터베이스 설계의 데이터 명명 간 일관성
을 보장하고 업무와 시스템의 특성을 반영한다.
시스템 환경을 조사한다.
1. 시스템 구성 요소(데이터베이스, 서버, 네트워크, 스토리지, 운영체제 등)의 매뉴얼
이나 관련 사이트에 기록된 제원을 기반으로 제품의 특성과 시스템이 제공 가한
성능 사양 파악하기
(1) 시스템 구성 요소(서버, 네트워크, 스토리지 등)의 매뉴얼 및 관련 사이트상의 제
원에 대한 검토를 통해 제품이 제공하는 자원(성능, 특성 등)을 파악한다.
(2) 운영체제 및 DBMS 버전 확인을 통해 시스템의 제약이나 특성(파라미터 정보, 저
장 공간 및 메모리 관리기법, 옵티마이저 타입 등)을 파악한다.
2. 시스템 운영 모니터링 결과 확인을 통한 시스템 사용현황 및 성능과 특성 파악하기
(1) DBMS가 제공하는 기능 또는별도의 모니터링 시스템을 통해 데이터베이스 시스
템의 사용 현황에 대한 모니터링 결과를 확인 및 분석한다.
(2) 모니터링 결과의 분석을 통해 시스템 사용 현황 및 성능과 특성을 파악한다.
(3) 앞서 시스템 구성 요소의 제원을 통해 나타난 결과와 비교를 통해 사용의 특성
과 문제점 등을 진단한다.
데이터베이스 관리 요소 기반의 시스템을 조사 분석한다.
1. 데이터베이스 정책(관리 및 보안) 관련 자료의 확인을 통해 데이터베이스 관리 요
소 확인하기
데이터베이스 정책, 데이터아키텍처 정책 또는 데이터베이스 보안정책 등의 확인을
통해 데이터베이스 보안 정책 및 지원도구와 기이드라인 등을 확인하고, 내용을 검토
및 분석한다.
2. 데이터베이스 시스템 환경 조사 및 분석 결과를 기반으로 대상 데이터베이스의 특
성에 따른 관리 요소 확인하기
데이터베이스 시스템 환경 조사 결과를 기반으로 데이터베이스 시스템의 환경에 따
라 달라질 수 있는 관리 요소 및 데이터베이스 구조, 이중화 구성, 분산구조, 접근제
어, DB암호화 등의 내용에 대해 확인하다.
3. 확인된 데이터베이스 관리 요소를 기반으로 시스템 조사 분석결과를 정리하기
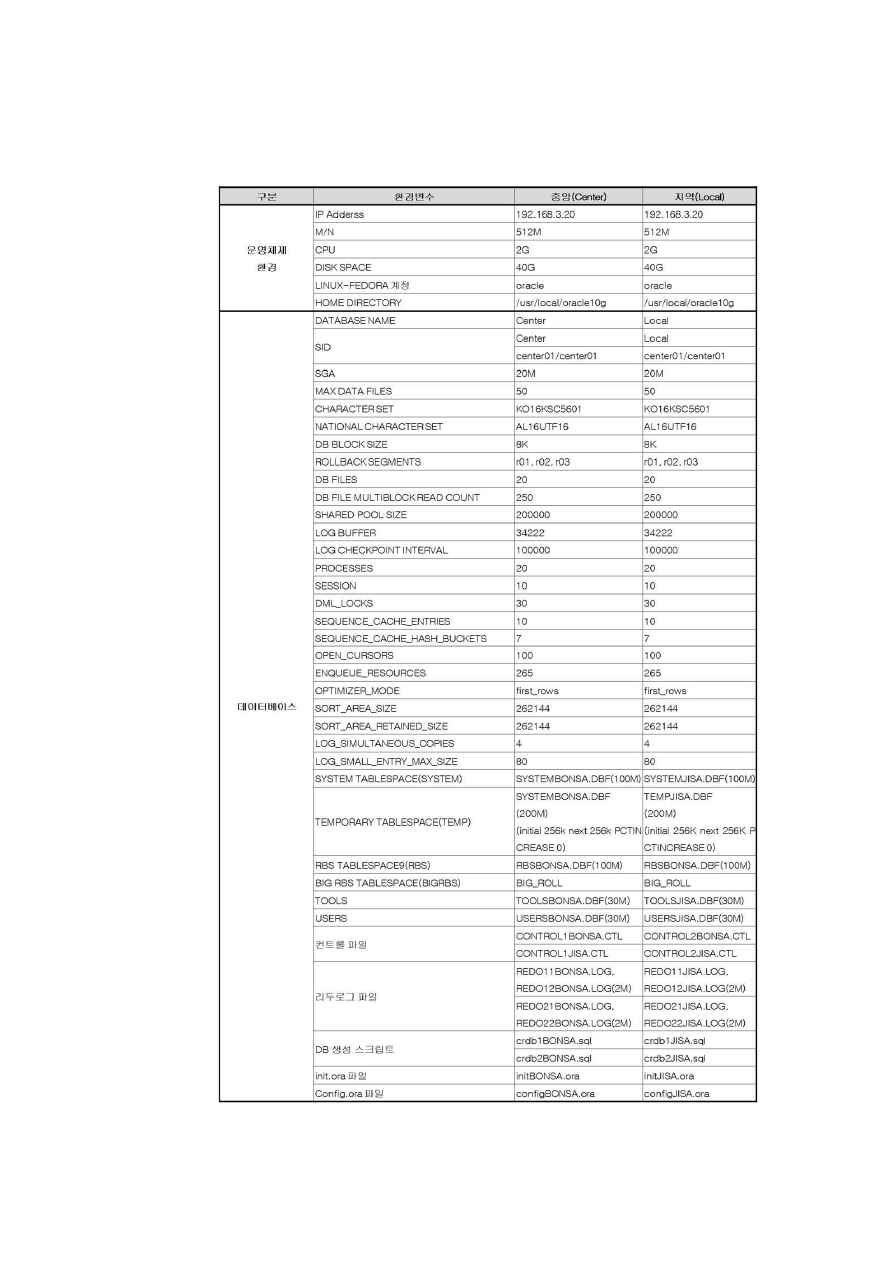
9
이후 물리 데이터베이스 설계 및 구현에 효과적으로 적용하고 참조하기 위해 관리 요소
에 대한 조사 및 분석결과를 숙지하고, 데이터베이스 시스템 조사 분석서를 작성한다.
[그림 1-1] 시스템 분석의 주요 내용 예시 (DB 구축가이드 참조, http://www.dbguide.net/,
한국데이터베이스진흥원)
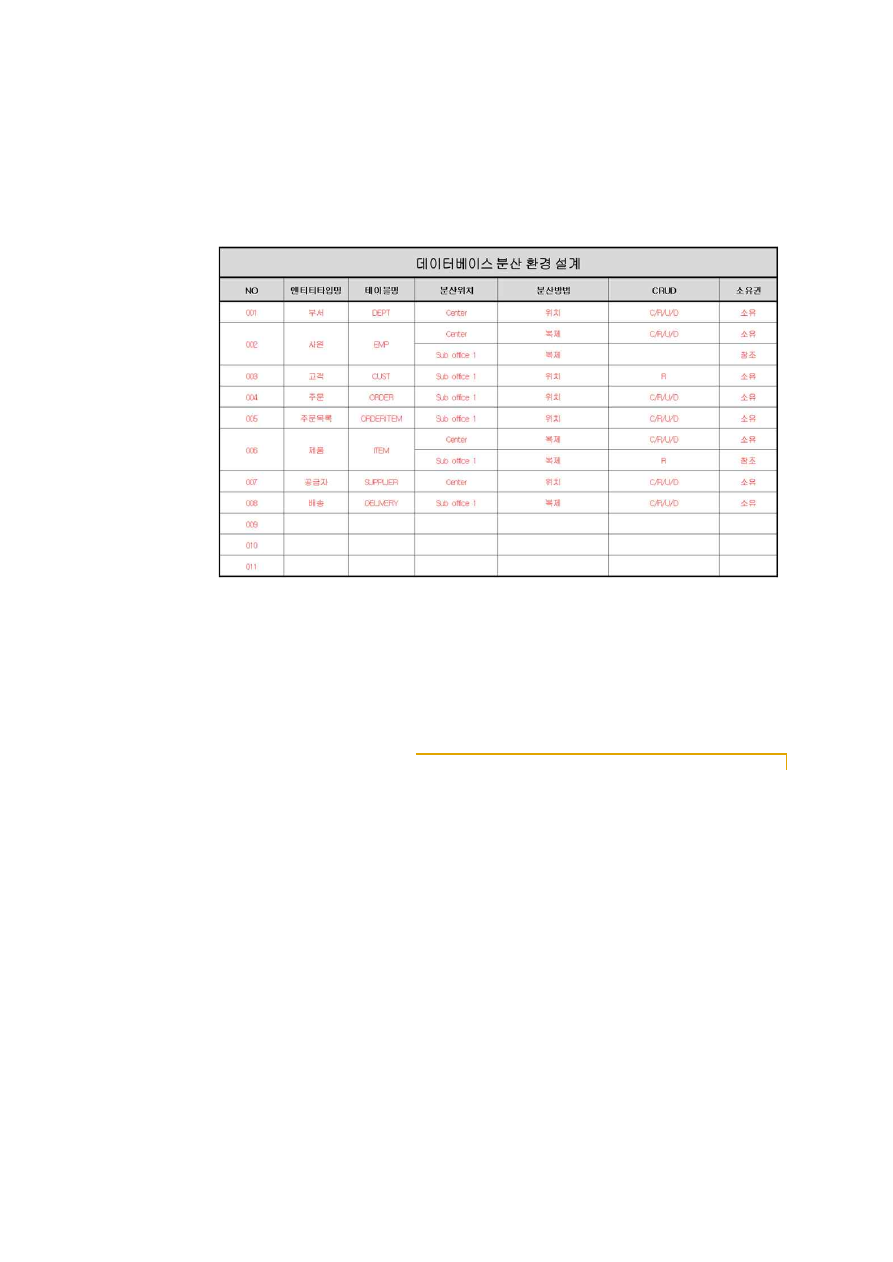
10
데이터베이스 시스템 조사 분석서의 내용은 데이터베이스 생성시 반영해야할 각종
환경에 대한 값을 기반으로 작성되며, 분산 시스템의 경우 분산 환경에 대한 내용이
추가될 수 있다.
[그림 1-2] 데이터베이스 분산 환경 설계의 주요 내용 예시
수행 tip
Ÿ
아키텍처 산출물을 통해 비즈니스영역과 시스템 영역에
대한 구성과 관계 등을 파악할 수 있다.
Ÿ
데이터 명명의 일관성을 확보하기 위해 명명 규칙에 대
한 파악과 적용은 논리 데이터베이스 설계 전 단계에서
수행하는 것이 효과적이다.
Ÿ
데이터베이스 환경설계서 작성 시 사용자 및 관리자에
대한 조사(인터뷰, 설문조사 등)을 통해 시스템 구성 요
소의 제원과 모니터링 결과로 알 수 없는 업무간 사용
특성을 파악할 수 있다.
Ÿ
상세화된 보안 정책과 지원도구, 가이드라인에 대한 확
인을 통해 시스템 조사 분석의 내용을 보다 쉽게 파악할
수 있다.
Ÿ
데이터베이스 환경설계서는 구현된 데이터베이스 시스
템의 물리 환경적 특성을 나타냄으로 관리 요소 파악에
활용할 수 있다.
11
학습 1
교수 ‧ 학습 방법
교수 방법
• 데이터 표준화 및 데이터 품질 관리의 정책(데이터베이스 및 보안 관련 정책 등)에 대한 학습자의
이해 정도를 파악 후 수업을 진행한다.
• 교수자는 효과적인 학습을 위해 ‘논리 데이터베이스 설계(2001020403_14v2)’와 연계하여 설명
한다.
• 논리 모델링의 결과 즉 산출물이 확보되어 있다면, 본 물리 모델의 교육 내용과 관련 사항을
리스트화 하여, 반드시 학습자에 설명한다.
• 대상 데이터베이스의 특성, 시스템 구성 요소(HW/SW/NW) 제원, 데이터베이스 정책, 논리 데이터
베이스 설계, 데이터 표준화 등에 대한 자료의 준비 상황을 확인하고 제공해야 한다.
• 교수자는 물리 환경요소에 따른 데이터베이스 구현의 변화를 학습자가 이해하고 있는지 확인해
야 한다.
• 교육상에 발생하는 산출물은 대부분 학습자가 사용하는 데이터베이스나 학습자가 속한 조직
및 업무에 따라 상이하게 달라질 수 있다. 따라서 형식보다 산출물에 포함되는 내용의 의미와
역할 등을 중심으로 설명한다.
• 교수자는 반드시 교육내용에 산출물에 대한 작업이 필요한 경우 해당 학습자가 업무중 주로
사용하는 데이터베이스 프로그램의 특성이 반영되거나 소속된 조직에서 현재 사용되는 형태의
산출물 양식을 참고하여 교육을 수행한다.
학습 방법
• 데이터 표준화의 개념을 숙지하고, 표준 용어 사전, 표준 단어 사전, 표준 도메인 사전, 표준
코드 사전에 대해 이해한다.
• 데이터 품질 관리의 데이터베이스 관리 정책 내용(데이터베이스 및 보안 관련 정책 등)을 숙지한다.
• 데이터베이스와 시스템 구성 요소(HW/SW/NW) 제원 및 특성을 이해한다.
• 데이터베이스 물리 환경과 요소별 특성과 물리 데이터베이스 설계에 미치는 영향을 이해한다.

12
학습 1
평 가
평가 준거
• 평가자는 피평가자가 수행 준거 및 평가 내용에 제시되어 있는 내용을 성공적으로 수행할 수
있는지를 평가해야 한다.
• 평가자는 다음 사항을 평가해야 한다.
학습 내용
평가 항목
성취수준
상
중
하
데이터 명명 규
칙 파악
- 기존 시스템을 분석하여 업무 영역과 시스템 영역으
로 구분하여 용어 사전 기반으로 명명 규칙을 파악
할 수 있다.
시스템 운영체계
및 자원 조사
- 서버, 네트워크, 스토리지 자원을 조사하고, 데이터
베이스가 설치될 시스템의 운영체계와 데이터베이스
버전을 확인할 수 있다.
데 이 터 베 이 스
시스템 조사 분
석서 작성
- 데이터베이스 운영과 관련된 관리 요소를 파악하고,
데이터베이스 구조, 이중화 구성, 분산 구조, 접근제
어, DB 암호화에 대한 시스템 조사 분석서를 작성할
수 있다.
평가 방법
• 서술형 시험
학습 내용
평가 항목
성취수준
상
중
하
데이터 명명 규칙
파악
- 용어 사전에 기반한 명명 규칙을 이해하고 있는가를
평가
시스템 운영체계
및 자원 조사
- 데이터베이스 설치를 위해 조사 및 분석되어야 하는
물리 환경과 운영 환경, 관리 요소 등의 내용에 대
해 이해하고 조사 방법을 알고 있는가를 평가.
• 포트폴리오
학습 내용
평가 항목
성취수준
상
중
하
데 이 터 베 이 스
시스템 조사 분
석서 작성
- 물리적 환경과 운영 환경, 관리 요소 등 에 대한 조
사 및 분석을 통해 시스템 조사 분석서를 작성할 수
있는가를 평가.

13
• 평가자 체크리스트
학습 내용
평가 항목
성취수준
상
중
하
데이터 명명 규
칙 파악
- 용어 사전을 기반으로 물리 데이터베이스 모델링의
데이터 명명 규칙을 파악하고 명명할 수 있는가를
평가.
시스템 운영체계
및 자원 조사
- 데이터베이스 설치를 위한 물리 환경과 운영 환경에
대해 이해하고 있고, 조사할 수 있는가를 평가.
데 이 터 베 이 스
시스템 조사 분
석서 작성
- 조사된 물리 환경과 운영 환경, 관리 요소 등에 대
한 시스템 조사 분석서를 작성할 수 있는가를 평가.
피 드 백
1. 서술형 시험
- 용어 사전에 기반한 명명 규칙을 이해하고 있는가를 확인하여 부족한 부분을 숙지하도록
한다.
- 데이터베이스 설치를 위해 조사 및 분석되어야 하는 내용에 대해 이해하고 조사 방법을
알고 있는가를 확인하여 부족한 부분을 숙지하도록 한다.
2. 작업 포트폴리오
- 작성된 데이터베이스 시스템 조사 분석서는 데이터베이스 설치를 위해 필요한 물리 환경
과 운영 환경, 관리 요소 등의 내용을 반영하고 있는가를 확인한다.
3. 체크리스트를 통한 관찰
- 용어 사전 기반의 데이터 명명을 수행할 수 있는가를 확인하여 부족한 부분을 보충하도
록 한다.
- 데이터베이스 설치를 위한 물리 환경과 운영 환경에 대해 조사할 수 있을 만큼 이해하고
있는가를 확인하여 부족한 부분을 보충하도록 한다.
- 조사 및 분석된 물리 환경과 운영 환경의 내용을 이해하고 데이터베이스 시스템 조사 분석
서를 작성할 수 있을 만큼 이해하고 있는가를 확인하여 부족한 부분을 보충하도록 한다.
14
학습 1
물리 속성 조사 분석하기
학습 2 데이터베이스 물리 속성 설계하기
학습 3
물리 E-R 다이어그램 작성하기
학습 4
데이터베이스 반정규화하기
학습 5
물리 데이터 모델 품질 검토하기
2-1. 데이터베이스 물리 속성 설계
학습 목표
• 식별된 오브젝트의 데이터 타입, 사이즈, 증가 용량을 고려하여 저장 공간을 산출하
고, 해당 오브젝트에 대한 테이블 스페이스를 할당할 수 있다.
• 할당된 테이블 스페이스 용량을 기반으로 디스크 저장 용량을 산정하고, 데이터베이
스 백업 주기, 방식에 따른별도 저장 공간 용량을 산정할 수 있다.
필요 지식 /
저장 공간 설계
1. 테이블(table)
(1) 테이블이란?
가장 기본적 데이터베이스 객체인 테이블은 행(Row)과 칼럼(Column)으로 구성되며, 데
이터베이스에서 모든 데이터는 테이블에 저장된다. 상용 DBMS에서 제공되는 테이블들
은 DBMS 제품마다 명칭과 기능 등에 조금씩 차이가 있으며, 데이터의 저장 형태와 파
티션 여부, 데이터의 유지 기간 등에 따라 테이블을 다양하게 분류할 수 있다.
(가) 일반 유형 테이블 (Heap-Organized Table)
대부분의 상용 DBMS에서 표준 테이블로 사용하고 있는 테이블 형태로, 테이블 내
에서 로우의 저장 위치는 특정 속성의 값에 기초하지 않고 해당 로우가 삽입될 때
결정된다.
(나) 클러스터 인덱스 테이블(Clustered Index Table)
기본 키(PK: Primary Key) 및 인덱스 키 값 등의 순서를 기반으로 데이터가 저장되는
테이블을 클러스터 인덱스(Clustered Index)라고 한다. 클러스터 인덱스(Clustered
Index)는 B 트리의 리프 노드에 RID 가 아닌 데이터 페이지가 있는 구조로 이뤄
진다.

15
검색하고자 하는 키 값의 순서로 정렬되는 데이터 페이지는 프리 패치가 가능하
고, 인덱스에서 테이블로 탐색 및 조회하는 경로가 상대적으로 단축됨으로 인덱스
를 이용하는 방법보다 데이터 액세스를 빠르게할 수 있다. 그러나 데이터가 입력
될 때 키 순서에 따라 지정된 위치에 저장이 이루어져야 하므로 데이터 페이지
유지에 많은 비용이 발생한다. 그리고 Heap 구조 테이블을 사용하던 중 클러스터
인덱스로 전환하게 되면 데이터 페이지의 갱신이 일어나고 모든 관련 인덱스의
RID가 클러스터 인덱스의 기본 키 (PK: Primary Key)로 변환됨으로 다수의 오버헤
드(Overhead)가 발생한다.
(다) 파티셔닝 테이블(Partitioned Table)
1) 파티셔닝(Partitioning)
파티셔닝(Partitioning)은 대용량의 테이블을 파티션(Partition)이라는 보다 작은
논리적인 단위로 나눔으로써 성능의 저하 방지 및 관리를 상대적으로 보다 용
이하게 하고자 하는 개념으로 파티셔닝(Partitioning) 방식에 따라 일반적으로 범
위 분할(Range Partitioning), 해시 분할(Hash Partitioning), 결합 분할(Composite
Partitioning) 등으로 나눠진다.
2) 파티셔닝(Partitioning)의 유의 사항
대용량 데이터 관리에 매우 효과적인 파티셔닝(Partitioning)이지만 무조건 파티
셔닝(Partitioning)만 시행한다고 파티셔닝(Partitioning)의 모든 장점을 얻을 수는
없다. 불량 인덱스가 처리 속도를 오히려 저하시키듯 파티션 키의 구성 방법에
따라 비효율을 높이는 결과를 초래할 수도 있어 파티션 키의 결정은 전략적 관
점에서 고려되어야 한다.
3) 파티션 키의 결정
첫째, 파티션 키는 액세스 유형에 따라 파티셔닝(Partitioning)이 이뤄지는 것을 고
려하여 선정해야 한다. 분포도가 낮아 인덱스의 사용이 곤란한 경우 테이블 스캔
이 이루어져야 하는데, 대상이 대용량 테이블일 경우 절대적 작업량으로 인해 성
능적 문제를 해소하기 어렵게 된다. 단, 이러한 경우 검색 범위와 파티션 단위가
일치하면 인덱스의 활용 없이 원하는 범위에 대한 데이터를 조회할 수 있게 된다.
둘째, 이력에 대한 데이터의 파티셔닝(Partitioning)의 경우 파티션 생성 및 소멸
의 주기를 일치시켜야 한다. 이력 관리 데이터는 데이터 관리 전략 및 업무 규
칙에 따라 수명이 소진되면별도의 저장장치에 저장이 이뤄지고, 데이터베이스에
서는 삭제가 이뤄진 된다. 즉, 활용 가치를 기준으로 이력 데이터의 생성 및 소
멸의 주기가 결정되므로 주기를 고려하여 데이터베이스를 정리해야 한다. 만약
삭제 대상 데이터가 복수의 파티션에 분산된 경우 대상 데이터의 추출 및 삭제
에 상대적으로 큰 노력과 시간이 필요할 것이다. 그러나 파티션이 데이터의 생

16
성 및 소멸의 주기와 일치하는 경우 파티션 대상의 작업을 수행하므로 관리가
쉬워질 수 있다.
(라) 외부 테이블(External Table)
외부 테이블(External Table)은 데이터베이스 내의 일반 테이블과 같은 형태로 이용
할 수 있는 데이터베이스의 객체이다. 데이터웨어하우스(DW: DataWarehouse)에서
ETL(Extraction, transformation, Loading)등의 작업에 유용하게 활용할 수 있는 테이
블이다.
(마) 임시 테이블(Temporary Table)
임시 테이블(Temporary Table)은 트랜잭션 및 세션별로 데이터를 저장하고 처리할
수 있는 테이블을 말한다. 저장된 데이터는 트랜잭션이 종료되면 사라지는 휘발성
의 속성을 보이며, 타 세션에서 처리되는 데이터의 경우에는 공유할 수 없다. 절차
적 처리를 위해 임시적으로 사용할 수 있는 테이블이다.
(2) 칼럼(Column)
칼럼은 테이블을 구성하는 요소로, 데이터 타입(Data Type) 및 길이(Length) 등으로 정
의된다. 데이터 타입(Data Type)은 데이터 일관성 유지에 가장 기본적 기능으로 표준
화된 도메인을 정의한 경우 그에 따라 데이터의 타입과 길이를 정의한다.
DBMS는 일반적으로 내장 및 확장 데이터 형식을 지원하는데, 내장데이터 형식은 문
자, 숫자, 시간, 대형 객체 등을 정의할 수 있고 확장 데이터 형식은 행, 컬렉션, 사용
자 정의, 데이터 형식 등을 지원하고 있다.
비교 연산에서 두 칼럼 사이에 데이터 타입과 길이가 다른 경우 DBMS는 내부적으로
데이터 타입을 변형한 후 비교 연산을 수행해야 하므로 칼럼이 상호 참조 관계일 경
우 가능한 동일한 데이터 타입과 길이를 사용해야 한다. 만약 상호 다른 데이터 타입
을 사용한 경우 조인 또는 비교 연산에 인덱스가 있어도 사용이 어렵게 되거나 실행
계획을 예측할 수 없게될 수 있다.
(가) 칼럼 데이터 타입에 따른 물리적 순서조정
- 고정 길이 칼럼이고 NOT Null 인 칼럼은 앞편에 정의
- 가변 길이 칼럼은 뒤편에 배치
- Null 값이 많을 것으로 예상되는 칼럼을 뒤편으로 배치
(나) DBMS별 물리적 순서조정의 특성
물리적 순서조정은 DBMS마다 차이가 있지만 값이 변경될 때 체인(Chain) 발생을
억제하고 저장 공간의 효율적인 사용을 위해 필요하다.
1) 오라클의 경우
- 인덱스를 구성하고 있는 모든 칼럼의 값이 Null 인 로우는 인덱스에 저장하지
않는다.

17
- Null 과의 비교는 IS Null 혹은 IS NOT Null 을 통해서만 가능하다.
- 오라클의 Null 처리 장점은 인덱스의 저장 공간을 절약하고 테이블을 전체 범
위 스캔으로 쉽게 유도할 수 있다.
2) SQL 서버의 경우
- Null 도 하나의 값으로 인식하고 관리하므로 인덱스를 구성하는 모든 칼럼 값
이 Null 인 경우도 인덱스에 저장된다.
- Null 과의 비교도 ansi_Null s 옵션을 적용하면 equal 연산자로도 비교가 가능
하다.
- SQL 서버의 Null 처리 장점은 is Null 또는 is not Null 같은 조건으로도 인덱
스를 사용할 수 있다는 점이다.
ansi_Null s 옵션
- set ansi_Null s off 실행 시: where col1 = Null 과 같은 형태의 비교가 가능
- set ansi_Null s on을 실행 시 오라클과 마찬가지로 is Null 또는 is not
Null 형태의 비교만 가능.
(다) 데이터 타입과 길이 지정 시 고려 사항
- 가변 길이 데이터 타입은 예상되는 최대 길이로 정의한다.
- 고정 길이 데이터 타입은 최소의 길이를 지정한다
- 소수점 이하 자리 수의 정의는 반올림되어 저장되므로 정확성을 확인하고 정의
한다.
(라) DBMS별 문자열 비교 방법
DBMS마다 차이는 어느 정도 있을 수 있지만 일반적으로 문자열 비교 방법은 크게
두 가지로 구분할 수 있다. 길이가 작은 칼럼 끝에 공백을 추가하여 길이를 같게한
후 비교하는 방식과, 공백의 추가 없이 비교하는 방식이다.
1) 오라클의 경우
- 비교 대상 칼럼이 모두 CHAR, NCHAR, 문자 상수인 경우나 사용자 정의 함
수에 의하여 리턴된 값일 경우에는 공백을 추가 후 비교하는 방식을 사용한다.
- 비교 대상 값 중에 VARCHAR2 혹은 NVARCHAR2가 존재하면 공백 추가 없
이 비교를 수행한다.
- 비교 대상 칼럼의 길이가 서로 다르면 짧은 칼럼의 길이까지 비교하고 길이가
긴 칼럼을 크다고 판단하므로 CHAR와 VARCHAR2를 비교할 경우 VARCHAR2
의 칼럼이 길이보다 짧은 값이 입력된 데이터는 동일한 데이터 값이 들어 있
어도 서로 다른 값으로 인식한다.
2) SQL 서버의 경우
- SQL 서버는 ANSI_PADDING 옵션에 의해 공백 추가 여부가 결정된다. ON으로

18
설정할 경우 오라클과 동일한 방식이 저장에 활용되지만 OFF로 설정할 경우
CHAR와 VARCHAR 타입 모두 저장된 문자열 값에서 후행 공백이 지워진다.
- SQL 서버에서 ANSI_ PADDING을 ON으로 설정하고 CHAR와 VARCHAR를 비
교할 경우 오라클과는 다르게 길이보다 짧은 값이 입력된 데이터도 동일한
데이터로 인식한다.
3) 데이터 타입의 변환 비교
- 서로 다른 데이터 타입을 비교할 경우 오라클과 SQL 서버는 내부적으로 우선
순위가 높은 데이터 타입으로 변환하여 비교를 수행한다.
* CHAR & NUMBER 데이터 타입 변환 비교
- 데이터 타입이 NUMBER 경우 CHAR인 경우보다 우선순위가 높기 때문에
내부적으로 데이터 타입을 CHAR에서 NUMBER로 변환하여 비교한다.
- 문자열 칼럼에 알파벳이 등이 혼용되어 변환이 어려운 경우 SQL 오류가
발생된다.
- Like를 사용한 비교의 경우 비교 연산에 적용되는 데이터 대상을 문자열로
변환하여 비교를 수행한다.
예제: CHAR & NUMBER 데이터 타입의 Like를 사용한 비교
- NUMBER 데이터 타입과 비교되는 CHAR 데이터 타입에 숫자로 변환
이 불가능한 문자를 포함하고 있는 경우 앞선 예제와 같은 변환 비교가
불가능함.
- Like를 사용한 경우 대상을 모두 문자열로 변환하여 비교하므로 비교가
가능해짐.
2. 테이블(Table) & 테이블스페이스(Table space)
(1) 테이블(Table)
테이블(Table)은 테이블스페이스(Table space)라는 논리적 단위를 활용하여 관리하고,
테이블스페이스(Table space)는 물리적인 데이터 파일을 지정하여 저장된다. 테이블
(Table), 테이블스페이스(Table space), 데이터 파일로 분리하여 관리하는 경우 논리적
구성이 물리적 구성에 종속되지 않고 투명성에 대한 보장이 가능하다.
(2) 테이블 스페이스(Table space)
데이터베이스에 저장되는 내용에 따라 테이블스페이스(Table space)는 테이블, 인덱스,
임시(Temporary) 등의 용도로 구분하여 설계한다. 이는 백업 및 공간 확장 단위인 물
리적 파일 크기의 적정한 유지를 위해서다. 따라서 테이블스페이스(Table space)는 데
이터 용량을 관리하는 단위로 이용할 수 있다.
(가) 테이블 스페이스 설계 유형(데이터 / 인덱스 용도)
- 테이블이 저장되는 테이블스페이스(Table space)는 업무별로 지정한다.

19
- 대용량 테이블은 독립적인 테이블스페이스(Table space)를 지정한다.
- 테이블과 인덱스는 분리 저장한다.
- LOB(Large Object) 타입 데이터는 독립적인 공간을 지정한다.
3. 용량설계
(1) 용량설계의 목적
용량설계의 목적은 정확한 데이터 용량을 예측하여 저장 공간의 효과적으로 사용하
고 확장성을 보장하여 가용성을 높이기 위함이다.
H/W 특성을 고려한 용량설계를 통해 디스크 채널 병목을 최소화할 수 있다.
디스크 I/O를 분산한 용량설계를 통해 접근 성능을 향상시킬 수 있다.
용량설계를 통해 테이블 및 인덱스별로 적합한 저장 옵션을 지정할 수 있다.
(2) 테이블 저장 옵션의 고려 사항.
초기 사이즈, 증가 사이즈
트랜잭션 관련 옵션
최대 사이즈와 자동 증가
수행 내용 / 물리 데이터베이스 용량 산정하기
재료·자료
Ÿ
논리 데이터베이스 설계 산출물, 시스템 및 데이터베이스 구조정보, 보유한 데이터베이스 매뉴얼
및 가이드북
기기(장비 ・ 공구)
Ÿ
문서 작성 도구, 컴퓨터, 데이터베이스 운영 장비, 데이터베이스 프로그램, SQL 프로그램
안전 ・ 유의 사항
20
수행 순서
데이터베이스 용량 설계를 위한 용량을 분석한다.
1. 용량 분석의 목적 이해하기
정확한 용량을 산정하여 디스크 사용의 효율을 높여야 한다.
업무량이 집중되어 있는 디스크를 분리하여 설계함으로써 집중화 된 디스크에 대
한 입출력 부하를 분산시켜야 한다.
입출력 경합을 최소화하여 데이터의 접근 성능을 향상시켜야 한다.
데이터베이스 오브젝트의 익스텐트 발생을 줄여야 한다.
2. 기초 데이터 수집하기
분산(지역)별, 엔티티 타입명, 테이블명, 로우 길이, 보존기간, 초기건수 및 발생건수,
발생 주기, 연 증가율 등 용량 분석을 위한 기초자료를 수집한다.
초기 사이즈, 증가 사이즈: 데이터베이스의 초기 및 증가 사이즈
트랜잭션 관련 옵션: 데이터베이스에서 제공 및 생성된 옵션
최대 사이즈와 자동 증가: 데이터베이스에서 제공 및 설정한 최대 사이즈 및 자동증가
3. 기초 데이터를 이용하여 DBMS에 이용하는 오브젝트별로 용량 산정하기
오브젝트별 용량을 산정하기 위해 파악할 사항으로는 오브젝트 설계와 테이블스페이
스, 디스크 등의 용량산정을 파악해야 한다.
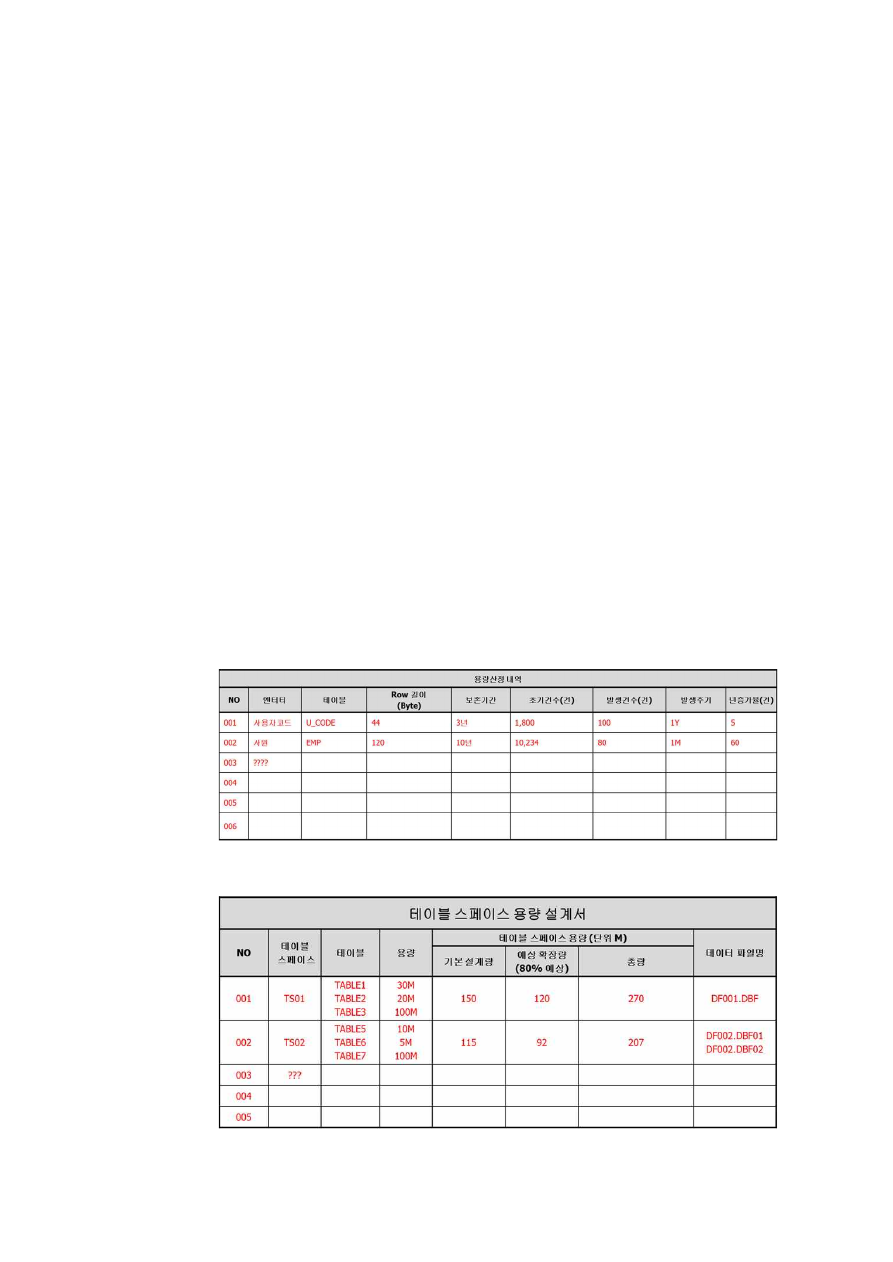
[그림 2-1] 용량산정 예시
[그림 2-2] 테이블 스페이스 용량 설계 예시
21
[그림 2-3] 파일 용량 설계 예시
[그림 2-4] 디스크 용량 설계 예시
(1) 테이블 용량 계산하기
테이블 용량을 계산하기 위해서는 시스템이 자동으로 제공하는 수준과 테이블 생
성에 소요되는 다음과 같은 사항을 파악해야 한다.
주로 데이터베이스의 블록과 관련된 계산이며, 블록의 사이즈는 일반적으로 테이
블스페이스 생성시 지정된다.
- 총 블록 헤드 계산
- 블록당 가능한 데이터 영역 계산
- 평균 Row의 전체 길이 계산
- 총 평균 Row 크기 계산

22
- 데이터 블록 내의 평균 Row 수 계산
- 테이블에 요구하는 블록과 바이트 수를 계산
(2) 인덱스 용량 계산하기
앞서 언급된 타 용량계산과 유사하다. 인덱스에 설정된 용량을 계산하기 위해 다
음과 같은 사항을 고려한다.
- 총 블록 헤더 계산
- 블록당 가능한 데이터 영역 계산
- 결합된 열 길이 계산
- 인덱스 값 크기의 전체 평균 계산
- 인덱스 값 크기의 전체 평균 계산
23
2-2. 물리 데이터베이스 설계서 작성
학습 목표
• 분산위치, 엔티티명, 테이블명, 테이블 스페이스명, 테이블 스페이스 용량, 데이터 파
일명, 파티셔닝, 클러스터링 정보, 보안정보에 대한 물리 데이터베이스 설계서를 작
성할 수 있다.
필요 지식 /
트랜잭션 분석
1. 트랜잭션이란?
데이터베이스에서 행해지는 작업의 논리적인 단위로써 테이블에 발생하는 업무 트랜잭션
양에 따라 데이터베이스의 용량을 산정하여 DB의 구조를 최적화하는데 트랜잭션 분석의
목적이 있다.
2. 트랜잭션 분석의 활용
(1) 용량산정의 근거자료.: 각각의 테이블의 생성 트랜잭션을 분석해 나가면 테이블에 저
장되는 데이터양을 유추할 수 있고 이를 근거로 DB용량을 산정할 수 있다
(2) 디스크 구성의 이용: 트랜잭션 분석 결과를 이용하여 프로세스가 과도하게 발생하는
테이블에 대해서는 디스크를 여러군데 배치하여 디스크 입출력을 분산시켜 성능에 많은
향상을 기할 수 있다.
(3) 테이터베이스와 연결되는 채널의 분산: 각각의 채널별로 집중화된 트랜잭션을 분산시
킴으로써 대기현상이나 TIME-OUT현상을 방지할 수 있다.
무결성 설계
1. 데이터 무결성
데이터 무결성 설계는 데이터의 정확성, 일관성, 유효성, 신뢰성 등과 무효 갱신으로부터
데이터를 보호 등을 위해 필요하다.
(1) 데이터 무결성 종류
(가) 실체 무결성
실체 무결성은 실체에서 개체의 유일성을 보장하기 위한 무결성으로 반드시 보장
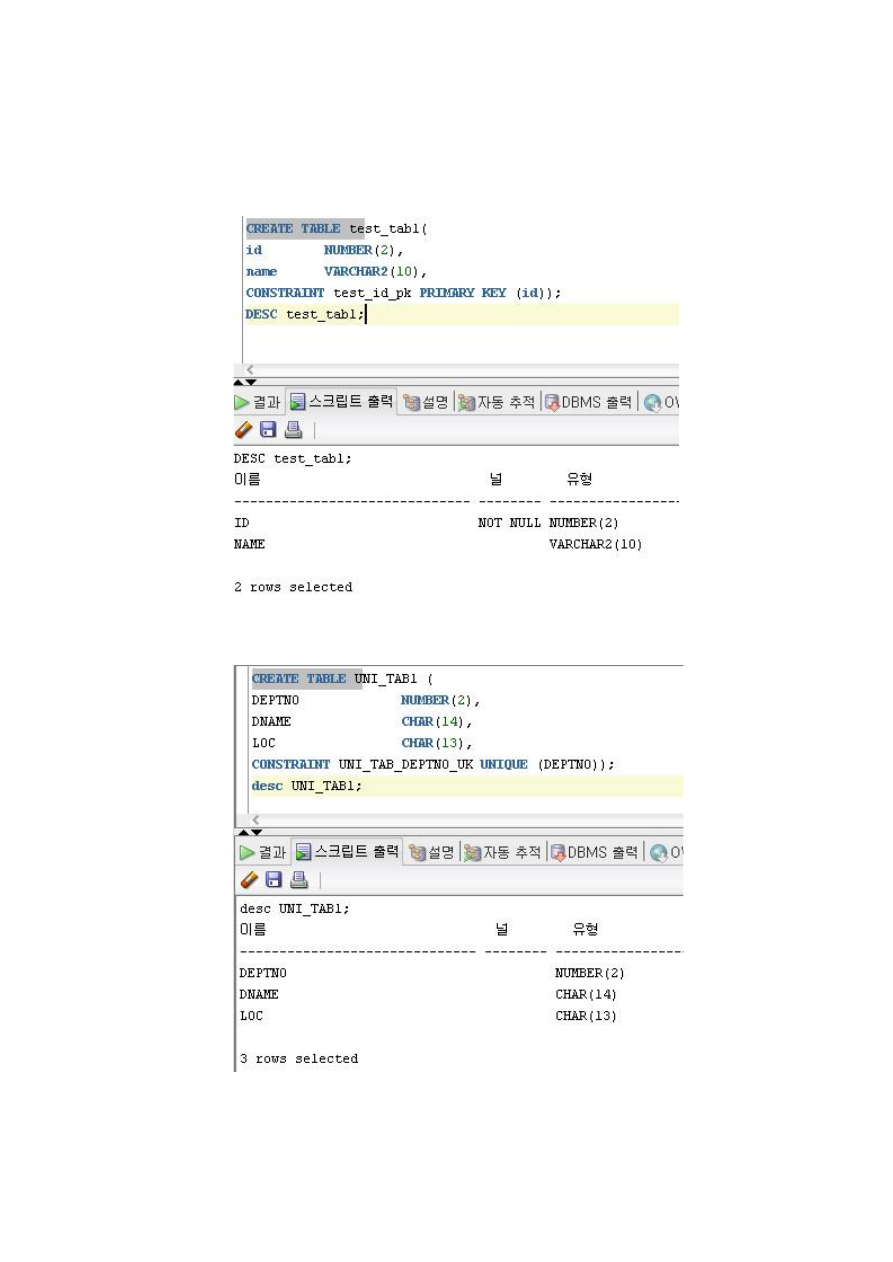
24
되어야 하므로 프로그램이나 트리거 등을 이용하는 것보다 데이터베이스에서 제공
하는 PK(Primary key) 제약 조건 과 Unique 제약 조건 등을 이용하여 보장하는 것
이 좋다. (기본 키 제약, UNIQUE 제약, 식별자 설계)
[그림 2-5] PK(Primary key) 제약 조건의 생성 및 결과 조회 예시
[그림 2-6] UK(Unique key) 제약 조건의 생성 및 결과 조회 예시

25
(나) 영역 무결성
칼럼 데이터 타입, 길이, 유효 값이 일관되게 유지되어야 한다. 영역 무결성은 칼럼
에 적용되어 단일 로우의 칼럼 값만으로 만족 여부를 판단할 수 있으며, 프로그램
소스와 제약 조건을 상호 보완적으로 사용을 하는 것이 효과적이다. (데이터 타입
(Data Type) & 길이(Length), 유효값(CHECK), Not Null )
(다) 참조 무결성
참조 무결성은 두 실체 사이의 관계 규칙을 정의하기 위한 제약 조건으로 데이터
가 입력, 수정, 삭 제될 때 두 실체의 튜플들 사이의 정합성과 일관성을 유지하는
데 사용된다. (입력 참조 무결성, 수정 삭제 참조 무결성, 디폴트 규칙 정의의 필요
성, 모델상에서 슈퍼 타입(SUPER-TYPE)-서브 타입(SUB-TYPE) 관계)
(라) 사용자 정의 무결성
다양하게 정의될 수 있는 비즈니스 규칙이 데이터적으로 일관성을 유지하는 것이다.
(2) 데이터 무결성 강화
데이터 무결성은 데이터 품질에 직접적인 영향을 준다. 데이터의 품질을 확보하고 유
지하기 위해서는 데이터베이스의 구축 과정에서 적정한 무결성 방안을 확보해야 한다.
그렇지 않은 경우 프로그램이 완성되고 데이터가 축적된 후 데이터 품질 문제로 인해
데이터 크랜징 및 무결성을 위한 방법을 강구할 때는 많은 비용이 발생된다.
데이터 무결성 제약의 정의는 데이터베이스에서 모두 이뤄질 수 없으므로 복잡한 규
칙을 기반으로 데이터 상호 간 유지해야할 정합성은 애플리케이션 내에서 처리 한다.
(가) 애플리케이션
데이터를 조작하는 프로그램 내에 데이터 생성, 수정, 삭제 시 무결성 조건을 검증
하는 코드를 추가한다.
1) 장점: 사용자 정의 같은 복잡한 무결성 조건을 구현함
2) 단점: 소스코드에 분산되어 관리의 어려움이 있음, 개별적으로 시행되므로 적정
성 검토에 어려움
(나) 데이터베이스 트리거
트리거 이벤트 시 저장 SQL을 실행하여 무결성 조건을 실행한다.
1) 장점: 통합 관리가 가능함, 복잡한 요건 구현 가능
2) 단점: 운영 중 변경이 어려움, 사용상 주의가 필요함
(다) 제약 조건
데이터베이스 제약 조건 기능을 선언하여 무결성을 유지한다.
1) 장점: 통합 관리가 가능함, 간단한 선언으로 구현 가능, 변경이 용이하고 유효/
무효 상태 변경이 가능함, 원천적으로 잘못된 데이터 발생을 막을 수 있음
2) 단점: 복잡한 제약 조건 구현이 불가능, 예외적인 처리가 불가능

26
인덱스 설계
1. 인덱스의 개념
인덱스는 검색 연산의 최적화를 위해 데이터베이스 내의 로우들에 대한 정보를 구성하는
데이터 구조이다. 인덱스를 활용하면 전체 데이터에 대한 검색이 없이 원하는 정보를 신
속하게 조회할 수 있다.
하나 이상의 데이터를 활용하여 비교 연산이 수행되는 방법 중 가장 효과적인 것은 정렬
후 값을 비교하는 것이다. 그러나 정렬이 비교 연산의 수행마다 이뤄지면 높은 비용이 발
생한다. 이러한 경우 정렬 결과를 효과적으로 유지하는 B 트리 형태로 정렬을 저장하면
비교 연산 수행마다 정렬하지 않고 이용할 수 있다.
(1) 인덱스의 주요 기능
인덱스를 통해 접근 경로를 단축함으로써 데이터 조회 속도를 향상시킬 수 있다. 데이
터의 조회는 데이터베이스에서 가장 중요하고 많이 사용되는 연산이므로 일반적으로
DBMS는 인덱스의 활용을 통해 조회 과정을 효율화 한다.
2. 인덱스 구조 설계
인덱스는 구성하는 구조나 특성을 기반으로 트리 기반, 해시 기반, 비트맵, 함수 기반 ,
조인, 도메인 등의 인덱스로 분류할 수 있다.
(1) 트리 기반 인덱스
일반적인 상용 DBMS의 경우 트리 구조 기반의 B+ 트리 인덱스를 주로 활용한다. B+
트리 인덱스의 경우 루트에서 리프 노드까지 모든 경로의 깊이가 일정한 밸런스 트리
(Balanced Tree) 형태로, 여타 인덱스와 비교할때 대용량 데이터의 삽입과 삭제 등 데
이터 처리에 좋은 성능을 유지한다.
(가) B 트리 인덱스
B 트리 인덱스의 경우 키 값이 트리에서 단 일회만 나타남으로 키 값을 순차적으
로 액세스하는 경우 트리 탐색에 높은 비용이 발생한다. 이러한 경우 트리 탐색 비
용을 최대한 감소하기 위해 B+ 트리는 전체 키 값을 리프 노드에 내리고 양방향으
로 연결(Doubly Linked List)하는 방식을 적용한다.
(나) B 트리 인덱스의 적용
B+ 트리 인덱스의 탐색 성능은 로우의 전체 수보다 이분화해 가는 깊이에 더 큰
영향을 받는다. 그러므로 이분화 수행에는 얼마나 처리 범위를 감소하느냐가 처리
깊이에 더 큰 영향을 주게 된다. 그런데 스캔의 경우 랜덤 액세스의 경우보다 비용
관점에서 유리함으로 얼마간 이분화를 수행하여 처리범위 감소가 확인된다면 이분
화 보다 스캔을 통한 비교가 유리하다.

27
그러므로 일반적인 상용 DBMS들은 일부 칼럼만 이분화를 진행한 후 인덱스 로우
의 스캔을 활용한다.
(다) B 트리 인덱스의 제약 조건
B+ 트리 인덱스는 삽입 및 삭제 등의 성능이 노드의 분할과 머지의 횟수에 영향
받기 때문에 노드의 분할 확률을 감소시키기 위해 제약 조건을 가진다.
이러한 제약 조건이 포함된 트리를 B* 트리라고 하며, 일반적인 상용 DBMS 대부
분에서 사용하고 있는 B 트리 인덱스는 B+와 B* 트리의 구조 및 특성을 모두 포함
하는 인덱스를 지원한다.
(2) 비트맵 인덱스(Bit-Map Index)
인덱스의 목적은 키 값을 포함하는 로우의 주소 정보를 제공하는 것이다. B+ 트리 인
덱스에서는 키 값별로 Rowid 리스트가 저장되어 인덱스의 목적을 달성하지만 비트맵
인덱스(Bit-Map Index)의 경우 B+ 트리 인덱스의 방식과는 차이가 있다.
비트맵 인덱스(Bit-Map Index)의 경우‘0’과 ‘1’로 이루어진 비트맵만으로 이뤄진
다. 비트맵에서 비트의 위치는 테이블에서 로우의 상대적인 위치를 의미하므로 해당
테이블이 시작되는 물리적인 주소를 기반으로 실제 로우의 물리적 위치를 계산할 수
있다. 일반적으로 DBMS는 내부적으로 비트의 위치를 가지고 로우의 물리적인 위치를
계산하는 함수를 지원한다.
비트맵 인덱스(Bit-Map Index)는 다중 조건을 만족하는 튜플의 개수 계산에 적합하다.
이것은 B+ 트리 인덱스에 비해 매우 작은 저장 공간과 비트 연산으로 이루어져 획기
적으로 줄어든 비교 연산 등의 비트맵 인덱스(Bit-Map Index)가 가진 장점 때문이다.
그 외 비트맵 인덱스(Bit-Map Index)의 장점으로 키 값 단위 생성으로 동일한 값이 반
복될 확률이 높아 압축 효율이 매우 좋다는 점을 들 수 있다.
(3) 함수 기반 인덱스(Function-based indexes)
함수 기반 인덱스(Function-based indexes)는 함수(function) 및 수식(expression)을 통해
계산된 결과에 B+ 트리 인덱스 또는 비트맵 인덱스(Bit-Map Index)를 생성하여 사용하
는 기능을 제공한다. 함수 기반 인덱스(Function-based indexes)의 함수에서는 산술식
(Arithmetic expression), PL/SQL Function, SQL Function, Package, C callout 적용이 가
능하지만 동일한 입력 값에 대해 시계열적 결과 값이 변경되는 함수의 경우에는 적용
되지 않는다.
Object Type의 경우 해당 칼럼별로 정의된 method에 대해 함수 기반 인덱스(Function-
based indexes)의 생성이 가능하다. 하지만 LOB, REF Type, Nested Table Column이나
이를 포함하는 Object type의 경우에는 함수 기반 인덱스의 생성을할 수 없다.
(4) 비트맵 조인 인덱스
단일 객체만으로 구성되는 일반적인 인덱스와 다르게 비트맵 조인 인덱스의 경우 다

28
수 객체의 구성 요소(칼럼)를 기반으로 인덱스의 생성이 이루어져 기존 인덱스의 테이
블 액세스 방법과는 구조가 다르다.
비트맵 조인 인덱스의 물리적 구조는 비트맵 인덱스와 동일하다. 단 인덱스 구성 칼럼이
베이스 테이블의 칼럼 값이 아니라 조인된 테이블의 칼럼 값이라는 점만이 다를 뿐이다.
(5) 도메인 인덱스
도메인 인덱스는 오라클의 버전 8i에서부터 도입된 개념으로 개발자 자신이 의도하는
인덱스 타입을 생성하는 것을 가능토록 하여 인덱스 시스템에 많은 확장이 가능하게
되었다.
데이터베이스는 존재하지도 않는 새로운 구조의 인덱스 타입에 대해 사용자 스스로
정의하여 DBMS에서 지원하는 인덱스처럼 사용할 수 있도록 해준다. InterMedia text
index나 오라클의 버전 9i부터 지원하는 Context 타입과 Catalog 타입 인덱스 등은 모
두 비정형 데이터의 빠른 검색을 위해 새롭게 도입된 도메인 인덱스다.
분산설계
1. 분산 데이터베이스
분산데이터베이스는 하나의 논리적 데이터베이스가 물리적으로 네트워크에서 복수의 컴퓨
터에 분산되어 있을 경우에도 사용자가 단일 데이터베이스와 같이 인식하는 것이 가능하
도록 논리적으로 통합 및 공유되는 데이터베이스를 의미한다.
분산 데이터베이스는 데이터베이스를 복수의 장소에 물리적으로 분산시켰으므로 이를 하
나의 논리적 데이터베이스로 인식시키기 위해서는 지역별 DBMS외에 각각의 장소의 정보
를 교환 및 관리 시켜주는 시스템이 필요하다. 이러한 역할의 시스템을 분산데이터베이스
관리 시스템이라고 한다.
(1) 분산 데이터베이스의 장점
데이터에 대한 지역적 분산 제어를 통해 원격 데이터에 대한 의존도를 감소시킬 수
있다. 단일 서버에서 처리가 어렵거나, 불가능한 규모의 대용량 데이터 처리가 가능해
지며, 기존 시스템에 서버를 추가하는 방식을 통해 점진적 확장이 용이하다. 또한 데
이터베이스를 사용중 하나의 사이트에 문제가 생겨 사용할 수 없는 상황이 발생해도
고장 난 사이트의 데이터외 타 사이트의 데이터는 사용이 가능해짐으로써 신뢰도와
가용성이 향상된다.
(2) 분산 데이터베이스의 단점
분산 처리에 의해 복잡도와 소프트웨어 개발 비용이 증가할 수 있고, 단일형 데이터베
이스에 비해 상대적으로 통제 기능이 취약하고, 분산 처리로 인한 오류 발생의 가능성
이 증가하게 된다. 또한 데이터가 물리적으로 저장된 장소와 해당 지역별 시스템에서

29
발생하는 상황의 영향으로 응답 속도가 불규칙적으로 나타날 수 있으며, 데이터의 무
결성을 완전히 보장하기 어렵다.
2. 분산 데이터베이스 관리 시스템
복수의 분할된 물리적 데이터베이스를 논리적으로 단일회된 데이터베이스처럼 인식하려면
사용자들이 데이터의 물리적 배치와 특정 지역 사이트의 데이터에 대한 액세스 방법을별
도로 알 필요가 없어야 한다. 이러한 특성을 데이터 투명성이라 하며, 분산 데이터베이스
관리 시스템은 다음과 같은 투명성이 제공될 수 있어야 한다.
(1) 분할 투명성
분할 투명성은 사용자에게 전역 스키마의 분할상태를 알려주는 역할을 한다. 사용자가
입력한 전역 질의를 여러 개의 단편 질의로 변환해 주기 때문에 사용자는 전역 스키
마가 어떻게 분할되어있는지를 알 필요가 없게 된다. 분할의 방법에는한 릴레이션을
속성들의 부분 집합으로 이루어진 릴레이션들로 나누는 수직 분할과, 튜플들의 집합으
로 이루어진 릴레이션들로 나누는 수평 분할 등으로 나뉜다.
(2) 위치 투명성
위치 투명성은 사용자나 애플리케이션에서 어떤 작업을 수행하기 위해 분산 데이터베
이스상에 존재하는 어떠한 데이터의 물리적인 위치도 알 필요가 없어야 한다는 것이
다. 사용자는 분산 환경과는 무관하게 동일한 명령을 사용할 수 있어야 한다.
분산 데이터베이스 관리 시스템은 위치 투명성을 보장하기 위해 분산 데이터베이스에
저장되어 있는 모든 데이터에 대한 메타 데이터와 위치 정보를 참조하여 지역 트랜잭
션의 경우에는 지역 데이터베이스를 처리하고, 전역 트랜잭션의 경우는 다른 지역의
데이터베이스에 처리를 일임하여 결과를 통보 받는다.
(3) 중복 투명성
중복 투명성은 중복된 데이터가 무엇인지와 저장 위치 등에 대한 정보를 사용자가별
도로 인지할 필요가 없어야 한다는 것이다. 사용하고 있는 데이터가 해당 사용자에 논
리적으로 유일하다고 생각할 수 있는 환경을 제공해야 한다.
중복과 위치 투명성을 통해, 분산 데이터베이스 관리 시스템은 사용자의 데이터 처리
요청에 대해 가장 효율적인 최적의 지역을 선정하여 처리할 수 있도록 하므로 수행
속도가 향상되지만 복제 데이터의 갱신을 처리하기 위해서는 복제된 모든 지역에 대
한 데이터 갱신이 이루어져야 하므로 무결성을 보장하기 어려워진다.
(4) 장애 투명성
장애 투명성은 데이터베이스의 분산된 물리적 환경에서 특정 지역의 컴퓨터 시스템이
나 네트워크에 장애가 발생해도 데이터 무결성이 보장된다는 것이다. 분산 데이터베이
스는 구성 요소의 장애에 무관하게 트랜잭션의 원자성이 유지되어야 한다.

30
(5) 병행 투명성
병행 투명성은 다수 트랜잭션이 동시에 수행되는 경우에도 결과의 일관성이 유지되어
야 한다는 것을 의미한다. 분산 데이터베이스 관리 시스템은 분산 트랜잭션의 일관성
유지를 위해 잠금(Locking)과 타임스탬프(Timestamp) 등의 방법이 주로 활용된다.
3. 분산 설계 전략
분산 데이터베이스는 사용자 및 애플리케이션 프로그램이 분산 환경의 각기 분리된 데이
터에 접근 가능하도록 하는 것을 목적으로 한다. 분산 데이터베이스는 설계가 잘못될 경
우 복잡성 및 비용의 증가와 불규칙한 응답 속도, 데이터 무결성의 어려움 등이 발생할
수 있다. 따라서 분산 데이터베이스 설계 시에는 분산 데이터베이스의 환경과 구조가 구
현된 시스템에 적합한지를 고려하여 설계해야 한다.
(1) 분산 설계 전략의 분류
일반적으로 수직 분할, 수평 분할, 복제의 세 가지 방법의 전략으로 분류되지만 데이
터의 분할 및 복제, 지역 복제본의 갱신 주기, 데이터베이스의 유지 방식 등에 따라
여러 가지 전략이 존재한다.
중앙 집중형 데이터베이스와 같이 하나의 컴퓨터만 데이터베이스를 관리하고 여타
지역은 접근이 가능하도록 하는 방식
지역 데이터베이스에 데이터를 복제하고 복제본을 실시간으로 갱신하는 방식과 주
기적으로 갱신하는 방식
분산 환경에서 전지역 데이터베이스를 단일의 논리적 데이터베이스로 유지하는 방식
분산 환경에서 각지역 데이터베이스들을 각각 독립적 데이터베이스로 유지하는 방식
4. 분산 설계 방법
분산 설계는 먼저 전역 관계망을 논리적 측면에서 중복되지 않는 소규모 단위로 분할하
고, 분할된 결과를 복수의 노드에 할당하는 과정으로 진행된다. 노드에 할당하는 경우 기
준이 되는 소규모 단위를 분할(Fragment)이라 부르며, 분할 스키마를 통해 전역 릴레이션
과의 사상(mapping) 관계를 관리한다.
분할(Fragment)이 할당될 때 하나의 분할(Fragment)이 분산 네트워크상에 있는 하나의 노
드에 1:1로 존재하도록 하여 단일 복사본(Single Copy) 또는 복제(Replication)를 통해 유지
할 수 있다. 이와 같이 분할(Fragment)은 분산 데이터베이스에 중복 또는 비중복되어 존
재하는데, 할당 스키마에 의해 분할(Fragment)이 위치하는 노드를 정의한다.
(1) 테이블 위치 분산
테이블을 중복되지 않게 분산 배치하는 것이다. 대상 테이블이 특정 서버에 존재할 경
우 여타 다른 서버에는 존재하지 않도록 설계하는 것이다. 이러한 설계를 위해서는 각
각의 테이블의 위치가 다르도록 지정하기 위해서 각각의 테이블마다 존재할 서버를
결정하여 설정해야 한다.

31
(2) 분할(Fragmentation)
분할(Fragment)은 분할을 위한 방법을 먼저 결정하고 결정된 분할을 할당하는 개념이다.
(가) 분할의 룰
완전성(Completeness)의 규칙은은 분할(Fragment) 시에 전역 릴레이션 내의 모든
데이터가 손실 없이 분할로 사상 (Mapping)되어야 하는 것으로 분할 대상이 전체
데이터를 대상으로 함을 의미한다.
재구성(Reconstruction)의 규칙은 분할이 관계 연산을 활용하여 본래의 전역 릴레이
션으로 재구성이 가능하여야 함을 의미한다.
상호 중첩 배제(Dis-jointness)의 규칙은 분할 시에 특정 분할에 속한 데이터 항목이
여타 분할 데이터 항목에 속하지 않아야 한다는 것을 의미하는 것으로, 수평 분할
은 각각의 분할에 포함된 튜플들이 상호 중복되지 않아야 하고, 수직 분할은 식별
자를 제외한 속성들이 중복되지 않아야 함을 의미한다.
(나) 주요 분할 방법
분할의 대표적인 방법은 수평분할과 수직 분할로 나눠진다. 수평분할의 경우 로우
(Row) 단위 분리로 즉, 특정 속성 값 기준의 분할을 의미한다. 속성 값으로 인해
서버 간 상호 배타적이므로 분할을 통합하는 상황에서도 중복 식별자는 발생하지
않는다.
수직 분할의 경우 데이터 칼럼 분할로 즉, 속성 자체로 기준이 되는 분할로 튜플
기준의 분리가 아니므로 서버별 동일 식별자를 가진 튜플이 중첩되게 존재한다. 식
별자가 동일한 구조를 포함하므로 식별자를 통해 분할 전 릴레이션의 재구성이 가
능하다.
(3) 할당(Al ocation)
할당(Allocation)은 동일한 분할을 복수 서버에 생성하는 분산 방법으로 중복이 없는 할
당(Allocation)과 중복이 있는 할당(Allocation) 방법 등으로 나뉜다.
(가) 비 중복 할당 방식
최적 노드의 선정을 통해 분할이 분산 데이터베이스에서 단일 노드에서만 존재하
도록 하는 것을 말한다. 그러나 애플리케이션은 릴레이션을 서로 배타적 분할로 분
리하는 것이 어려운 요구가 포함되는 경우가 일반적이므로 분할 간 상호 의존성은
무시되고 비용 증가 및 성능의 문제 등이 발생할 수 있다.
(나) 중복 할당 방식
중복되지 않는 할당으로 비용 증가와 성능에 문제가 발생된다면 각각의 노드의 분
할을 중복하여 할당하는 방법을 고려해야 한다.
복제의 경우 일부 분할만 복제하는 부분 복제와 전체 데이터베이스를 복제하는 완
전 복제 등 두 가지 방식의 구성이 가능하다.

32
5. 분산 설계와 데이터 통합
최적 비용을 통해 물리적으로 분산된 데이터베이스에서 데이터 일관성을 유지할 수 있는가
라는 측면에서 분산 설계는 출발했다. 대부분 통합의 경우 데이터 통합이라는 측면에서 분산
아키텍처의 단점 보완과 정보의 적시성 및 실시간 데이터 교환 등의 목적을 위해 통합 아키
텍처를 구축한다. 통합 방식은 DW를 활용하는 방법과 EAI(Enterprise Application Integration)
를 활용 두 가지 방법과 두 가지 방법을 혼용하여 통합하는 방법 등으로 나뉜다.
보안설계
1. 데이터베이스 보안
데이터베이스 정보가 허가받지 않은 사용자에 의해 노출 및 변조와 파괴 등이 되는 것을
방지하는 것을 데이터베이스 보안이라고 한다. 데이터베이스 보안으로 인해 사용자는 원
하는 작업을 수행하기 위해 필요한 자원을 활용에 대한 허가가 있어야 한다.
(1) 보안 설계 목표와 정책
보안 설계의 주요 목표는 비인가 사용자를 통한 정보 노출을 방지하고, 인가된 사용자
는 데이터 접근 및 수정이 가능하도록 보장하는 것이다. 이러한 목표를 달성하기 위해
서는 보안 정책이 수립에 일관성이 보장되어야 하며, 보안 정책은 보안 모델을 통해
운영체제와 DBMS를 통해서 보장되어야 한다.
(2) DBMS의 보안모델 기능
일반적인 DBMS는 데이터 보안의 유지를 위해 다양한 보안 모델의 기능(접근 통제 기
능, 보안 규칙, 뷰(View), 암호화 등)을 제공하고 있다.
(3) 보안 정책 수립의 고려 사항
(가) 자원에 접근하는 사용자 식별 및 인증 - 사용자, 비밀번호, 사용자 그룹
자원에 접근하는 사용자는 인증을 기반으로 실체가 보장되어야 한다. 만약 타인이
사용자의 실체를 인증 받아야 하는 경우가 발생하면 타인이 사용자의 인증을 사용
할 수 없어야 한다.
(나) 보안 규칙 / 권한 규칙에 대한 정의
보안 규칙은 특정 사용자가 접근 가능한 데이터와 데이터에 대하여 허용된 행위나
제한된 조건을 기록하는 것이며 보안 모델을 통해 구현된다.
(다) 사용자의 접근 요청에 대한 보안 규칙 검사 구현 - 보안 관리 시스템 구현
보안 규칙에 대한 검사 구현은 운영체제와 데이터베이스 관리 시스템을 활용하여
보장되어야 한다.
2. 접근 통제
접근 통제는 사용자가 특정 데이터에 접근할 때 접근을 요구하는 사용자에 대한 식별과

33
사용자의 요구 사항이 정상적인지에 대한 여부를 확인 및 기록하고 보안 정책에 근거 접
근을 승인하거나 거부하여 허가받지 않은 사용자의 불법적 자원에 대한 접근과 파괴 등의
행위를 예방하는 보안 관리의 모든 행위를 의미하는 보안 시스템 상의 주요한 기능적 요
구 사항 중 하나이다.
(1) 임의 접근 통제(DAC, Discretionary Access Control)
임의 접근 통제는 사용자의 신원 정보를 통해 권한의 부여 및 회수에 대한 메커니즘
을 기반으로 한다. 즉, 권한은 사용자가 특정 객체에 어떠한 행위를할 수 있도록 객체
와 행위에 대해 허용하는 것으로, 임의적 접근 통제에서 객체를 생성한 사용자는 생성
된 객체에 적용 가능한 모든 권한을 부여받게 되고, 부여된 권한들을 여타 사용자에게
허가할 수 있는 허가 옵션도 적용받게 된다. 그 외 다른 사용자의 경우 특정 객체에
대해 데이터 조작 행위를 위해서는 데이터베이스 관리 시스템으로부터 권한을 부여
받아야 한다.
[그림 2-7] 사용자에 대한 권한의 부여 실행 예시

34
(가) 임의 접근통제 지원을 위한 SQL 명령어
DBMS에서 지원하는 임의 접근 통제에 대한 SQL 명령어는 GRANT와 REVOKE 등
으로 나뉜다. GRANT 명령어는 객체에 대한 권한을 사용자에 부여하기 위해 활용
하고, REVOKE 명령어는 사용자에게 권한을 회수하는 상황에서 사용한다.
[그림 2-8] GRANT와 REVOKE 명령어를 사용한 권한 부여
및 삭제 실행 예시
(나) 임의 접근통제의 위험
임의적 접근 통제는 효과적인 권한 관리 방법이지만 관리 기반이 사용자 신분 정
보에 근거하므로 타인의 신분을 도용한 불법적인 접근이 이루어진다면 접근 통제
본래의 기능에 큰 결함이 발생할 수 있다. 따라서 보안 등급 기반의 데이터와 사용
자 분류는 부가적 보안 정책이 반드시 제시되어야 한다.
(2) 강제 접근 통제(MAC, Mandatory Access Control)
강제 접근 통제의 경우 주체와 객체를 보안 등급 중 하나로 분류하고, 주체가 사용자
보다 보안 등급이 높은 객체에 대한 읽기, 쓰기 등을 방지한다. 각각의 데이터베이스
객체에는 보안 분류 등급이 부여될 수 있고, 사용자별로 인가 등급을 부여할 수 있어
접근에 대한 통제가 가능하다. 일반적으로 읽기는 사용자의 등급이 접근하는 데이터
객체 등급과 같거나 높은 경우에만 허용되고, 수정 및 등록은 사용자의 등급이 기록하
려는 데이터 객체의 등급과 같은 경우만 허용한다. 이러한 통제는 높은 등급의 데이터
가 사용자를 통해 의도적으로 낮은 등급의 데이터로 사용되거나 복사되는 것을 방지
하기 위함을 목적으로 한다.
3. 보안모델
보안모델이란 보안 정책의 구현을 위한 이론적 모델로 대표적인 종류에는 군사적 목적으
로 개발된 기밀성 모델, 데이터 일관성 유지를 위한 무결성 모델, 접근 통제 메커니즘에
근거한 접근 통제 모델 등으로 나뉜다.

35
(1) 접근 통제 행렬(Access control matrix)
임의적 접근 통제를 관리하기 위한 보안 모델로, 행은 주체를, 열은 객체를 나타낸다.
따라서 행과 열은 주체 및 객체의 권한 유형을 나타낸다.
(가) 주체(행): 일반적으로 객체에 대하여 접근을 시도하는 사용자로 데이터베이스에
접근할 수 있는 조직의 개체를 의미한다.
(나) 객체(열): 보호되고 접근 통제가 이루어져야 하는 데이터베이스의 개체(테이블,
칼럼, 뷰, 프로그램, 논리적 정보 단위 등)를 나타낸다.
(다) 규칙: 주체가 객체에 대하여 수행하는 데이터베이스의 조작(입력, 수정, 삭제, 읽
기, 생성, 삭제 등)으로 객체가 프로그램으로 확장되는 경우 실행과 출력 등에
대한 작업 유형 정의가 가능하다.
(2) 기밀성 모델
기밀성 모델은 정보의 불법적 회손 및 변조 보다는 기밀성(Confidentiality)에 중점을 둔
수학적인 모델로, 여타 보안 모델과의 비교를 위해는 활용되지만 일반적인 상용 환경
에서는 기밀성 보다는 무결성의 중요성이 높아 부적합하고, 군대의 시스템 등 특수한
환경에서 사용되는 모델이다.
이 모델은 사용자, 계정, 프로그램 등의 주체와 릴레이션, 튜플, 속성, 뷰, 연산 등의
객체를 보안 등급(극비: Top Secret, 비밀: Secret, 일반: Confidential, 미분류:
Unclassified) 기준으로 분류하며, 데이터 접근에 대한 주체와 객체의 보안 등급을 근거
로 제약 조건을 준수해야 한다.
(가) 데이터 접근 제약 조건
Ÿ
단순 보안 규칙: 주체는 자신보다 높은 등급의 객체를 읽을 수 없다.
Ÿ
★(스타)-무결성 규칙: 주체는 자신보다 낮은 등급의 객체에 정보를 쓸 수 없다.
주체가 높은 등급의 정보를 낮은 등급으로 복사하여 유출을 시도하는 것을 방
지하기 위함으로 정보의 기밀성 보호를 위한 제약이다.
Ÿ
강한 ★(스타) 보안 규칙: 주체는 자신과 등급이 다른 객체에 대하여 읽거나 쓸
수 없다.
(3) 무결성 모델
기밀성 모델에서 정보 비밀성을 위해 정보의 일방향 흐름 통제를 활용하는 경우 발생
가능한 정보의 부당 변경 등을 방지하기 위한 보안 모델이다. 기밀성 모델과 같이 주
체 및 객체의 보안등급을 기반으로 하며, 제약 조건 역시 유사하게 적용된다.
(가) 무결성 모델 제약 조건
단순 보안 규칙: 주체는 자신보다 낮은 등급의 객체를 읽을 수 없다.
★(스타)-무결성 규칙: 주체는 자신보다 높은 등급의 객체에 정보를 쓸 수 없다.

36
4. 접근통제 정책
접근 통제 정책은 어떤 주체(Who)가 언제(When), 어떤 위치에서(Where), 어떤 객체(What)
에 대하여, 어떤 행위(How)를 하도록 허용할 것인지 접근 통제의 원칙을 정의하는 것으로,
신분-기반 정책, 규칙-기반 정책, 역할-기반 정책 등으로 나뉜다.
(1) 신분 기반 정책은 개인 또는 그들이 속해 있는 그룹들의 신분에 근거하여 객체에 대
한 접근을 제한하는 방법이다.
- IBP(Individual-Based Policy): 단일 사용자가 하나의 객체에 대해 허가를 부여받는 경우
- GBP(Group-Based Policy): 복수 사용자가 하나의 객체에 대하여 같은 허가를 함께
부여받는 경우
(2) 규칙 기반 정책은 강제적 접근 통제와 동일한 개념으로, 주체가 갖는 권한에 근거하
여 객체에 대한 접근을 제한하는 방법이다.
- MLP 정책: 사용자 및 객체가 각각 부여된 기밀 분류에 따른 정책
- CBP 정책: 조직 내 특정 집단별로 구분된 기밀 허가에 따른 정책
(3) 역할 기반 정책은 GBP의한 변형된 형태로 정보에 대한 사용자의 접근이 개별적인 신
분이 아니라 개인의 직무 또는 직책에 따라서 결정되는 방법이다.
5. 접근 통제 매커니즘
사용자 통제를 기술적으로 구현하는 방법은 패스워드, 암호화, 접근 통제 목록 적용, 제한
된 사용자 인터페이스, 보안 등급 등의 방법이 이용된다.
6. 접근 통제의 조건
접근 통제 매커니즘의 보완을 목적으로 접근 통제 정책에 적용할 수 있는 조건들로, 특정
임계 값, 사용자 간 동의, 사용자 특정 위치 및 시간 등에 대한 지정이 가능하다.
(1) 값 종속 통제(Value-Dependent Control): 일반적인 통제 정책들의 경우 저장된 데이터
값에 영향을 받지 않지만 상황에 따라 저장 값을 근거로 접근 통제를 관리하는 경
우도 발생한다.
(2) 다중 사용자 통제(Multi-User Control): 특정 객체에 대해 복수 사용자가 함께 접근 권
한을 요구하는 경우 다수 사용자에 대한 접근통제 지원 수단이 필요하다.
(3) 컨텍스트 기반 통제(Context-Based Control): 특정 외부요소(특정 시간, 네트워크 주소,
접근 경로, 위치, 인증 수준 등)에 근거하여 접근을 관리하는 방법으로 여타 보안 정
책과 결합하여 보안 시스템을 보완한다.
7. 감사 추적
감사 추적은 데이터베이스에 접속한 애플리케이션 및 사용자의 모든 활동을 기록으로 만

37
드는 기능이며, 오류로 인한 데이터베이스의 복구 및 부당한 조작을 파악하기 위한 목적
으로 활용할 수 있다.
즉, 개인 책임성 보조와, 문제 발생시 사건의 재구성이 가능하며, 사전에 침임 탐지를 확
인한다거나 사후 문제를 분석하여 보안을 강화하기 위해 활용할 수 있다.
감사 추적 시에는 사용자 및 사용에 대한 정보(실행 프로그램, 클라이언트, 날짜 및 시간,
접근 데이터의 이전 및 이후 값 등)를 저장한다.

38
수행 내용 / 물리 데이터베이스 설계서 작성하기
재료·자료
Ÿ
시스템 조사 분석서, 물리 데이터베이스 설계서 또는 관련 자료
기기(장비 ・ 공구)
Ÿ
문서 작성 도구, 컴퓨터 및 데이터베이스 운영 장비, 데이터베이스 프로그램, SQL 프로그램
안전 ・ 유의 사항
수행 순서
데이터베이스 설계서를 작성한다.
1. 테이블 스페이스 설계하기
테이블을 마스터 테이블과 트랜잭션 테이블로 분류한다.
예상 레코드 건수에 따라 2~4개로 분류한다.
시스템의 구성(Disk의 구성)에 따라 테이블스페이스의 개수와 사이즈 등을 결정한다.
분류에 따라 테이블스페이스의 용량을 결정하고 Storage를 결정한다.
OS상으로 Striping 되어 있는 않는 경우는 테이블스페이스의 작은 사이즈의 여러
개의 데이터파일로 구성할 수 있다.
수평분할(Partition)할 테이블은별도로 분류한다.
테이블스페이스의 Extents Size를 테이블에서 동일하게 적용하거나 정수배로 결정한다.
Locally Management Tablespace 생성을 고려한다.
테이블 객체를 위한 테이블 스페이스와 인덱스 객체를 위한 테이블스페이스를 분
리구성 한다.
2. 테이블 설계하기
(1) Entity를 table로 전환하기
일반적으로 TABLE 명칭과 ENTITY 명칭은 동일하게 전환한다.
필요에 따라 ENTITY 명칭은 한글로 하고 동의어를 영문으로 표시한다.
사례표 (instance chart)에 TABLE의 역할을 간략하게 표현한다.
SUPER-TYPE 이나 SUB-TYPE은 나중에 결정한다.
(2) Attribute를 Column로 전환하기
칼럼의 명칭은 속성의 명칭과 반드시 일치할 필요는 없으나 가능한 표준화된
39
약어를 사용한다.
주식별자를 Primary Key로 외부 식별자는 Foreign Key로 설정한다.
SQL의 예약어(reserved word)를 사용하지 않아야 한다.
가능한 칼럼 명칭은 짧은 것이 좋으며 짧은 명칭은 SQL 해독시간을 감소시킨다.
필수입력 속성은 Null s/Unique 란에 NN을 표시한다.
용어 사전과 도메인 정의에 따라 설계한 속성을 그대로 칼럼으로 사용한다.
DATE 타입은 DATE연산이나 LOGGING, 시간 계산이 요구하는 경우에 사용하
고 날짜 계산이 요구하는 칼럼은 문자로 지정한다.
자기 참조 칼럼의 최상위는 Null 로 지정하지 않고 ‘*’로 지정(인덱스 사용을
위해)한다.
Default의 지정으로 코딩의 단순화와 데이터 무결성을 보장한다.
(3) Constraint 설정 장점을 이해한다.
데이터베이스 성능을 향상 시킨다.
선언과 변경이 가능하다.
활성화/ 비활성화할 수 있다.
요구 사항과 Rule의 통제가 가능하다.
(4) Constraint의 종류를 확인한다.
Not Null / Unique / 칼럼 Check조건 / 테이블 Check 조건 / Primary Key /
Foreign Key
[그림 2-9] Constraint (Foreign Key) 실행 예시

40
3. 인덱스 설계하기
설계 단계에서는 Primary Key와 Foreign Key 및 테이블 접근 경로가 분명하게 드러
나는 칼럼에 대해서 기본적인 인덱스를 지정하고, 개발 단계에서 SQL 문장 구조를
검토하여 반복적으로 인덱스 설계를 진행한다.
(1) 인덱스 설계 순서
(가) 인덱스 대상 선정
(나) 인덱스 최적화
(다) 인덱스 정의서 작성
(2) 인덱스 대상 테이블 선정
MULTI BLOCK READ 수에 의해 판단
MULTI BLOCK READ가 16일 때 테이블의 크기가 16블록 이상일 경우 인덱스 설정
MULTI_BLOCK_READ_COUNT는 8인 경우 (BLOCK SIZE 8K) 테이블의 크기가
64k이하이면 인덱스를 불필요. 그러나 참조 관계인 경우 인덱스를 생성
(3) 인덱스 대상 칼럼의 선정
분포도 = 데이터별 평균 로우 수 / 테이블 총 로우 수 * 100
분포도가 10~15%인 칼럼에 대해서 인덱스 지정
자주 사용하는 칼럼(ORDER BY, GROUP BY, UNION, DISTINCT)
인덱스 칼럼은 수정이 자주 발생하지 않는 칼럼을 선정하고, 분포도가 기형적 불
균형인 인덱스는 설정을 재고(Null 의 사용)한다.
데이터의 DML 작업이 많은 테이블의 경우 인덱스의 개수 5개 이하로 하며,
CHAR 형식은 VARCHAR2로 한다.
Date 타입은 ‘=' 연산의 경우가 드물며, Substr, Like연산이 불가능한 경우가 많다.
(4) 결합 인덱스
칼럼 순서가 중요
접근 경로가 '=' 연산이 가능한 칼럼이 앞으로
분포도 좋은 칼럼이 앞으로
정렬이 자주 발생하는 칼럼이 앞으로
4. 뷰 설계하기
(1) 테이블 구조의 단순화를 추구한다.
(2) 다양한 관점에서의 데이터를 제시한다.
(3) 데이터의 보안 유지를 고려한다.
(4) 논리적인 데이터의 독립성 유지를 고려한다.

41
(5) 뷰의 대상을 선정한다.
인터페이스 정의서의 외부 시스템과 인터페이스 관여하는 테이블
Crud Matrix를 통해 여러 테이블을 동시에 자주 조인하는 접근하는 테이블
SQL문 작성 시 거의 모든 문자에서 인라인 뷰 방식으로 접근하는 테이블
5. 클러스터 설계하기
지정된 칼럼 값의 순서대로 데이터 행을 저장하는 방법으로, 하나 혹은 그 이상의 테
이블을 같은 클러스터내 저장이 가능하다. 액세스 기법이 아니라 액세스 효율 향상을
위한 물리적 저장 방법으로, 검색 효율은 높여주나 입력, 수정, 삭제 시는 부하가 증
가할 수 있다.
분포도가 넓을수록 오히려 유리 (인덱스의 단점을 해결)하고, 분포도가 넓은 테이블의
클러스터링은 저장 공간의 절약이 가능하다.
(1) 클러스터링은 다음의 경우에 고려한다.
6 블록 이상의 테이블에 적용
대량의 범위를 자주 액세스하는 경우
인덱스를 사용한 처리 부담이 되는 넓은 분포도
여러 개의 테이블이 번번히 조인을 일으킬 때
반복 칼럼이 정규화에 의해 어쩔 수 없이 분할된 경우
Union, Distinct, Order by, Group by 가 빈번한 칼럼이면 고려
수정이 자주 발생하지 않는 칼럼
(2) 테이블 클러스터링 방법을 사용한다.
처리 범위가 넓어 문제가 발생하는 경우는 단일 테이블 클러스터링, 조인이 많아
문제가 발생되는 경우는 다중 테이블 클러스터링 방법을 사용한다.
6. 파티션(Partition) 설계하기
(1) 테이블 파티션
파티션 설계는 파티션의 종류 결정, 파티션 키의 선정, 파티션 수의 결정의 순서
로 진행된다.
대용량 DB는 몇 개의 중요한 트랜잭션 테이블에서 데이터가 증가한다. 이것을 보
다 작은 단위로 나눔으로써 성능 저하 방지와 관리를 수월하게할 수 있다.
(가) 테이블 파티션의 장점.
데이터 액세스 범위를 줄여 Performance 향상
전체 데이터의 훼손 가능성이 감소 및 데이터 가용성 향상
각각의 분할 영역을 독립적으로 백업하고 복구가능

42
Disk Striping로 I/O Performance를 향상(Disk 암에 대한 경합의 감소)
(나) 파티션 종류(오라클의 경우)
범위분할(Range Partitioning): 지정한 열의 값을 기준으로 분할
해시분할(Hash Partitioning): 해시 함수에 따라 데이터를 분할
조합분할(Composite Partitioning): 범위분할에 의해 데이터를 분할한 다음 해
시 함수를 적용하여 다시 분할하는 방식
(2) 파티션 키의 선정
I/O 분산을 처리하기 위해 액세스 유형에 따라 파티셔닝이 이루어질 수 있도록 파
티션 키를 선정한다. 이력 데이터의 경우에는 생성 주기 또는 소멸 주기가 파티션
과 일치한다.
(3) 인덱스 설계하기
(가) Local prefixed partitioned index
인덱스 칼럼의 구성에서 선두 칼럼이 파티션 키 칼럼인 인덱스로 각각의 파티
션에 분리된 값의 기준(파티션 키)에 따라 정렬되어 인덱스가 구성된다.
(나) Local non-prefixed partitioned index
인덱스의 선두 칼럼이 파티션 키 칼럼으로 시작하지 않는 로컬 인덱스로 파티
션 키가 포함되지 않은 칼럼들로 유니크 인덱스를 만들고자할 경우는 글로벌
인덱스가 구성된다.
(다) Global prefixed partitioned index
전체적인 활용 측면 및 영향을 충분히 고려하여 설계하고 생성해야 한다. 파티
션 테이블이 Drop되면 Index Rebuild가 필요하며, 파티션 키를 포함하지 않으
면서 몇 개의 칼럼이 결합된 유니크 인덱스를 만들어야할 때 구성된다.
(라) Global prefixed non-partitioned index
인덱스가 Partitioned 되어 있지 않은 형태로 일반적인 형태이다. 일반적인 파
티션 키를 포함한다.
7. 데이터베이스 설계서 작성하기
설계서에 주요 내용인 각각의 양식은 소속된 조직 및 현재 사용 중인 양식을 기준으
로 활용한다.
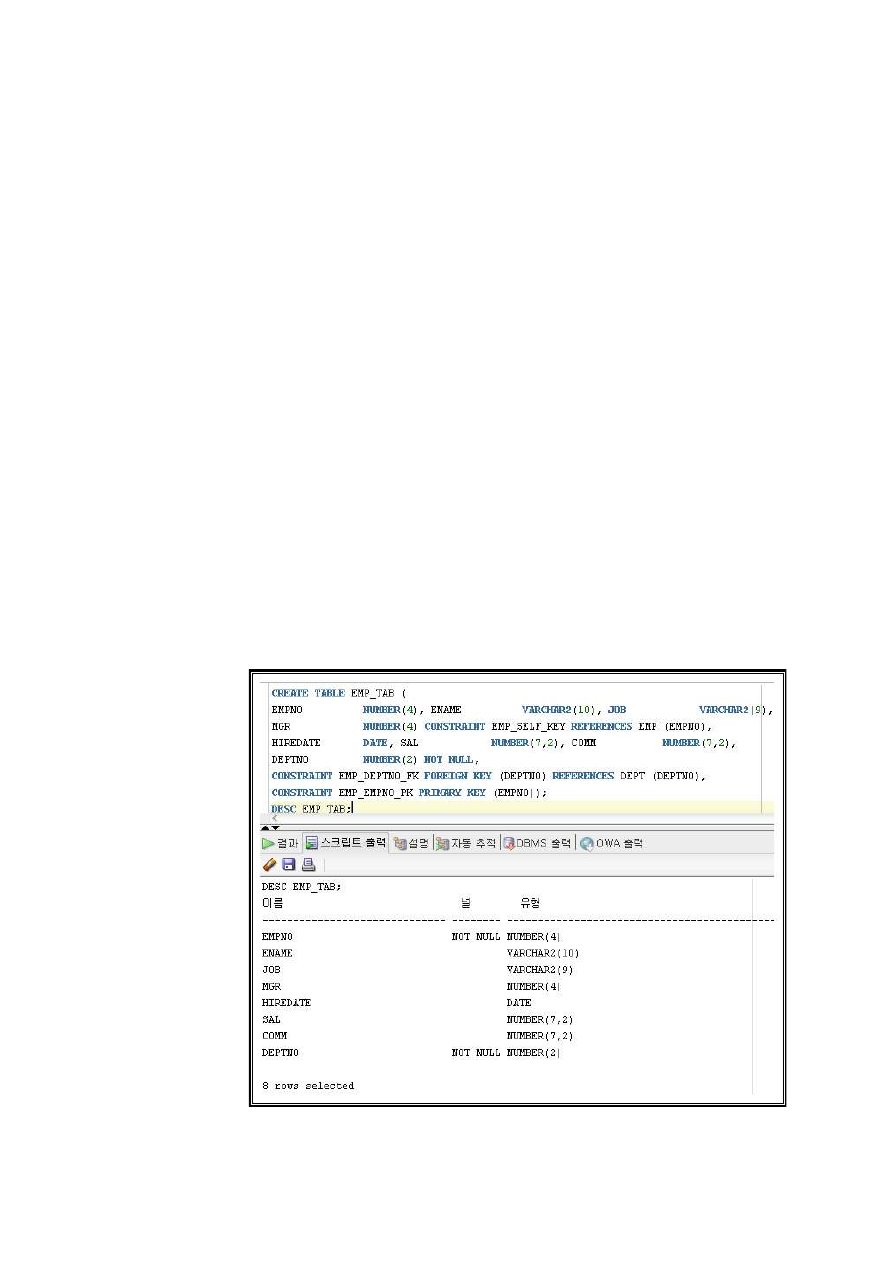
(1) 앞선 수행의 결과를 기반으로 테이블 정의서를 작성한다.
생성 테이블에 대한 정보를 정의한다.
43
[그림 2-10] 테이블 정의서 예시
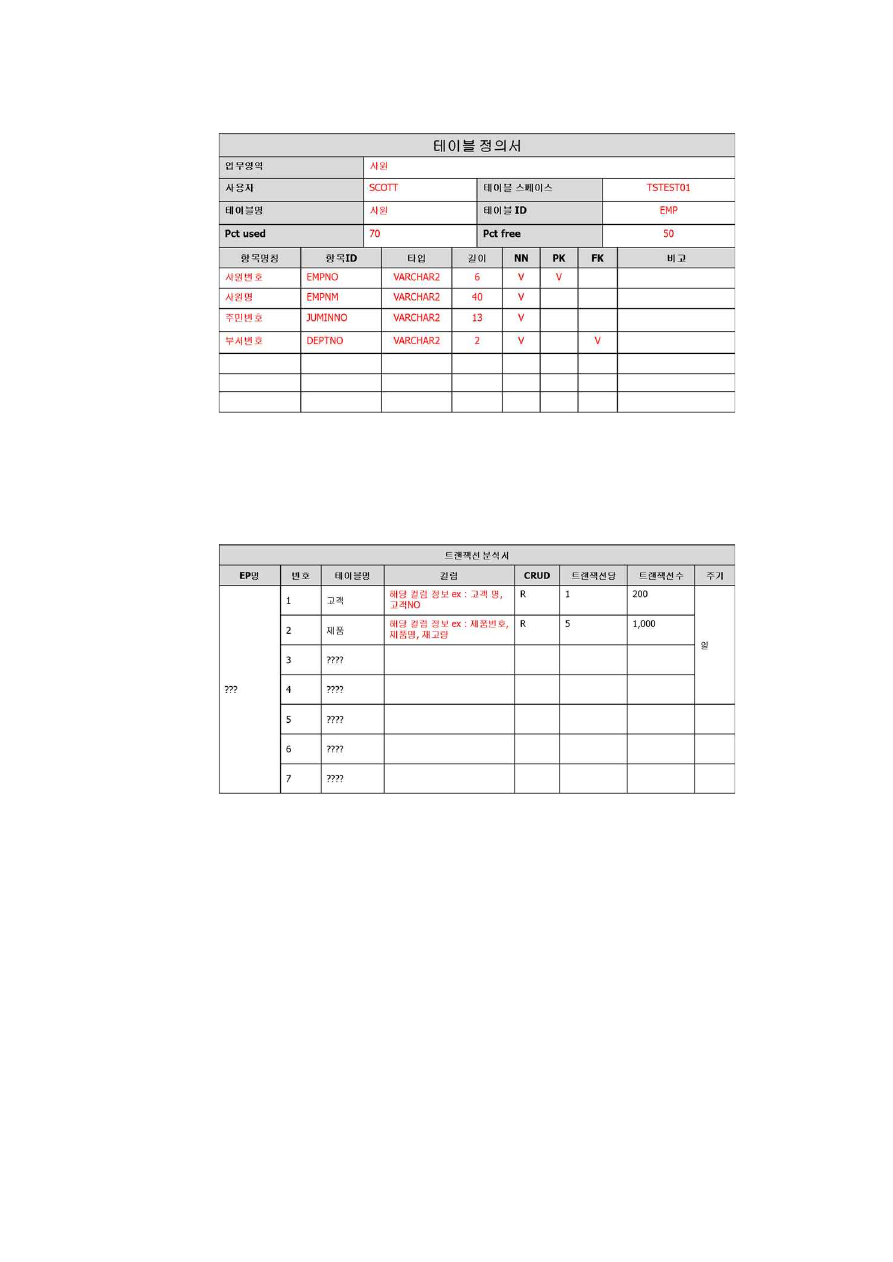
(2) 트랜잭션 분석서를 작성한다.
생성 트랜잭션의 정보를 정의한다.
[그림 2-11] 트랜잭션 분석서 예시
(3) 뷰 정의서를 작성한다.
생성 뷰 정보를 정의한다.
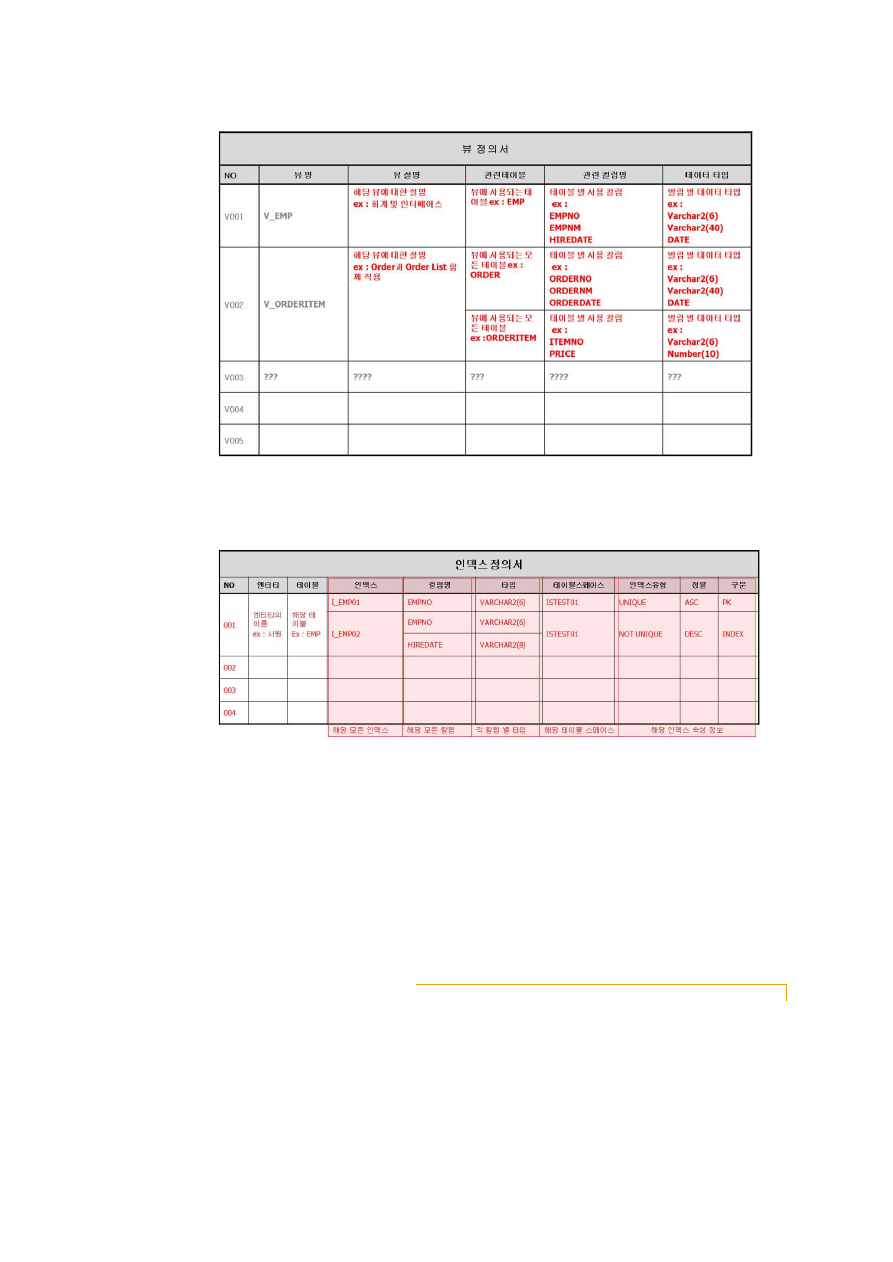
44
[그림 2-12] 뷰 정의서 예시
4. 인덱스 정의서를 작성한다.
[그림 2-13] 인덱스 정의서 예시
수행 tip
Ÿ 학습자가 사용하는 데이터베이스에 따라 특성이 달
라질 수 있다.
Ÿ 사전에 기존 데이터베이스의 구조 등의 정보에 대
해 파악해야한다.
45
학습 2
교수 ‧ 학습 방법
교수 방법
• 교수자는 사전에 학습자의 논리데이터베이스 산출물에 대한 이해 수준을 파악해야한다.
• 교수자는 효과적인 학습을 위해 ‘논리 데이터베이스 설계(2001020403_14v2)’와 연계하여 설명
한다.
• 논리 모델링의 결과 즉 산출물이 확보되어 있다면, 본 물리 모델의 교육 내용과 관련 사항을
리스트화 하여, 반드시 학습자에 설명한다.
• 사용가능한 데이터베이스별 특성과 활용이 달라질 수 있으므로 충분히 고려하여 사전에 해당
데이터베이스의 가이드 및 매뉴얼을 숙지한다.
• 교육상에 발생하는 산출물은 대부분 학습자가 사용하는 데이터베이스나 학습자가 속한 조직
및 업무에 따라 상이하게 달라질 수 있다. 따라서 형식보다 산출물에 포함되는 내용의 의미와
역할 등을 중심으로 설명한다.
• 교수자는 반드시 교육내용에 산출물에 대한 작업이 필요한 경우 해당 학습자가 업무중 주로
사용하는 데이터베이스 프로그램의 특성이 반영되거나 소속된 조직에서 현재 사용되는 형태의
산출물 양식을 참고하여 교육을 수행한다.
학습 방법
• 논리데이터모델링 산출물과 기존 데이터베이스의 구조정보를 충분히 고려한다.
• 데이터베이스 물리 환경과 요소별 특성과 물리 데이터베이스 설계에 미치는 영향을 이해한다.
• 데이터베이스 설계서는 기존 사용 양식 등을 참조하여 관련 정보를 상세하게 정의한다.
• 학습자는 교육내용상 제시되는 산출물이나 참고 자료의 형태가 본인이 주로 사용하는 데이터베
이스 프로그램이나 소속된 조직의 업무 양식과 다를 수 있음을 인지하고 형식보다 포함된 속성의
의미와 필요성을 이해해야 한다.
46
학습 2
평 가
평가 준거
• 평가자는 피평가자가 수행 준거 및 평가 내용에 제시되어 있는 내용을 성공적으로 수행할 수
있는지를 평가해야 한다.
• 평가자는 다음 사항을 평가해야 한다.
학습 내용
평가 항목
성취수준
상
중
하
데 이 터 베 이 스
물리 속성 설계
- 식별된 오브젝트의 데이터 타입, 사이즈, 증가 용량
을 고려하여 저장 공간을 산출하고, 해당 오브젝트
에 대한 테이블 스페이스를 할당할 수 있다.
- 할당된 테이블 스페이스 용량을 기반으로 디스크 저
장 용량을 산정하고, 데이터베이스 백업 주기, 방식
에 따른별도 저장 공간 용량을 산정할 수 있다.
물리 데이터베
이스 설계서 작
성
- 분산위치, 엔티티명, 테이블명, 테이블 스페이스명,
테이블 스페이스 용량, 데이터 파일명, 파티셔닝, 클
러스터링 정보, 보안정보에 대한 물리 데이터베이스
설계서를 작성할 수 있다.
평가 방법
• 서술형 시험
학습 내용
평가 항목
성취수준
상
중
하
데이터베이스 물
리 속성 설계
- 식별된 오브젝트의 데이터 타입, 사이즈, 증가 용량을
고려하여 저장 공간을 산출하고, 해당 오브젝트에 대
한 테이블 스페이스를 할당할 수 있는가를 평가.
- 할당된 테이블 스페이스 용량을 기반으로 디스크 저
장 용량을 산정하고, 데이터베이스 백업 주기, 방식에
따른별도 저장 공간 용량을 산정할 수 있는가를 평가.
물리 데이터베이
스 설계서 작성
- 분산위치, 엔티티명, 테이블명, 테이블 스페이스명, 테
이블 스페이스 용량, 데이터 파일명, 파티셔닝, 클러
스터링 정보, 보안정보에 대한 물리 데이터베이스 설
계서를 작성할 수 있는가를 평가.
47
• 포트폴리오
학습 내용
평가 항목
성취수준
상
중
하
물리 데이터베
이스 설계서 작
성
- 분산위치, 엔티티명, 테이블명, 테이블 스페이스명,
테이블 스페이스 용량, 데이터 파일명, 파티셔닝, 클
러스터링 정보, 보안정보에 대한 물리 데이터베이스
설계서를 작성할 수 있는가를 평가.
• 평가자 체크리스트
학습 내용
평가 항목
성취수준
상
중
하
데 이 터 베 이 스
물리 속성 설계
- 식별된 오브젝트의 데이터 타입, 사이즈, 증가 용량을
고려하여 저장 공간을 산출하고, 해당 오브젝트에 대
한 테이블 스페이스를 할당할 수 있는가를 평가.
- 할당된 테이블 스페이스 용량을 기반으로 디스크 저장
용량을 산정하고, 데이터베이스 백업 주기, 방식에 따
른별도 저장 공간 용량을 산정할 수 있는가를 평가.
물리 데이터베이
스 설계서 작성
- 분산위치, 엔티티명, 테이블명, 테이블 스페이스명,
테이블 스페이스 용량, 데이터 파일명, 파티셔닝, 클
러스터링 정보, 보안정보에 대한 물리 데이터베이스
설계서를 작성할 수 있는가를 평가.
피 드 백
1. 서술형 시험
- 식별된 오브젝트를 고려하여 저장 공간 산출 및 해당 오브젝트에 대한 테이블 스페이스를
할당 등에 필요한 내용을 숙지하고 있는가를 확인하여 부족한 부분을 숙지하도록 한다.
- 디스크 및별도 저장 공간 용량 산정에 필요한 내용을 숙지하고 있는가를 확인하여 부족한
부분을 숙지하도록 한다.
- 물리 데이터베이스 설계서 작성에 필요한 내용을 숙지하고 있는가를 확인하여 부족한 부분
을 숙지하도록 한다.
2. 작업 포트폴리오
- 물리 데이터베이스 설계서 작성을 위한 요소별 정의서와 설계서 작성을할 수 있는가를 확
인한다.
3. 체크리스트를 통한 관찰
- 식별된 오브젝트를 고려하여 저장 공간 산출 및 해당 오브젝트에 대한 테이블 스페이스를
할당 등에 필요한 내용을 이해하고 있는가를 확인하여 부족한 부분을 보충하도록 한다.
- 디스크 및별도 저장 공간 용량 산정에 필요한 내용을 이해하고 있는가를 확인하여 부족한
부분을 보충하도록 한다.
- 물리 데이터베이스 설계서 작성에 필요한 내용을 이해하고 있는가를 확인하여 부족한 부분
을 보충하도록 한다.
48
학습 1
물리 속성 조사 분석하기
학습 2
데이터베이스 물리 속성 설계하기
학습 3 물리 E-R 다이어그램 작성하기
학습 4
데이터베이스 반정규화하기
학습 5
물리 데이터 모델 품질 검토하기
3-1. 물리 ERD의 변환과 작성
학습 목표
• 논리 데이터베이스 설계에서 엔티티, 속성, 주식별자, 외래식별자를 각각 테이블, 칼
럼, 기본 키, 외래 키로 변환하여 표현할 수 있다.
• 물리 E-R 다이어그램 작성 툴로 도출된 테이블, 칼럼, 키 값을 도식화하고 설계서를
작성할 수 있다.
• 엔티티명, 속성 명에 대한 Data dictionary(용어 사전) 정의하고, 테이블명, 칼럼명,
키 종류, Nul 값 허용여부 정보를 기준으로 테이블 기술서를 작성할 수 있다.
필요 지식 /
논리 데이터 모델의 물리 데이터 모델로 변환
1. 엔티티 & 테이블 변환
(1) 테이블
데이터를 저장하기 위해서 생성된 데이터베이스의 가장 기본적 오브젝트다.
(가) 테이블(Table)
테이블은 기본적으로 칼럼(Column)과 로우(Row)를 가지며 각각의 칼럼은 지정된
유형의 데이터 값을 저장하는데 사용된다.
(나) 로우(Rows)
테이블의한 로우에 대응하여 튜플이나 인스턴스 또는 어커런스라고도 한다.
(다) 칼럼(Columns)
각 속성 항목에 대한 Value를 저장한다.
(라) 기본 키(Primary keys)
단일 혹은 복수 칼럼 조합으로 활용할 수 있으며, 유니크한 속성을 갖는다.

49
(마) 외래 키(Foreign keys)
외부 데이터 집합과의 관계를 구현한 구조를 위해 활용한다.
<표 3-1> 구성 요소의 변환 관계
논리적 설계 (데이터 모델링)
물리적 설계
데이터베이스
엔티티(entity)
테이블 (table)
테이블
속성 (attribute)
칼럼 (column)
칼럼
주 식별자(primaryidentifier)
기본 키(primary key)
기본 키
외래식별자(foreign identifier)
외래 키(foreign key)
외래 키
관계(relationship)
관계(relationship)
-
관계의 카디날리티
관계의 카디날리티
-
관계의 참여도
관계의 참여도
(2) 서브 타입 변환
논리 데이터 모델에서는 비즈니스나 업무를 데이터 모델로 표현하므로 최대한 상세하
게 표현한다.
따라서 일반적으로 가능한 엔터티 구성을 서브 타입으로 상세하게 표현한다. 아울러
각각의 서브 타입이 독립적인 속성(Attribute), 관계(Relationship)를 포함하는 경우 반드
시 서브 타입을 사용하여 집합을 표현해야한다. 이러한 논리 모델링의 서브 타입은 물
리 모델링에서 테이블의 형태로 설계된다.
(가) 슈퍼 타입 변환
서브 타입을 슈퍼 타입에 통합하여 하나의 테이블로 만드는 것을 말한다. 이러한 테
이블에는 서브 타입의 모든 데이터를 포함하고, 주로 서브 타입에 적은 양의 속성이
나 관계를 가진 경우에 적용된다
1) 단일 테이블 통합으로 유리한 경우
데이터의 액세스가 상대적으로 용이하다.
뷰를 이용하여 각각의 서브 타입 만을 액세스하거나 수정할 수 있다.
수행 속도가 좋아지는 경우가 많다
서브 타입 구분이 없는 임의 집합에 대한 가공이 용이하다.
다수의 서브 타입을 통합하는 경우 조인이 감소할 수 있다.
복잡한 처리를 하나의 SQL로 통합하기가 용이하다.
2) 단일 테이블 통합으로 불리한 경우
특정 서브 타입에 대한 NOT Null 제한이 어렵다.
테이블의 칼럼 및 블럭 수가 증가 한다.
처리마다 서브 타입에 대한 구분(TYPE)이 필요한 경우가 많이 발생 한다.
인덱스의 크기가 증가한다.

50
(나) 서브 타입 기준 변환
슈퍼 타입 속성들을 각각의 서브 타입에 추가하여 서브 타입마다 하나의 테이블로
만든다.
분할된 테이블은 해당되는 서브 타입 데이터만을 포함해야 한다.
주로 서브 타입에 다량의 속성 및 관계가 포함된 경우 적용된다.
1) 복수의 테이블로 분할이 유리한 경우
각 서브 타입 속성들의 선택 사양이 명확한 경우에 유리하다.
서브 타입 유형에 대한 구분을 처리마다할 필요가 없다.
전체 테이블을 스캔하는 경우 유리하다.
단위 테이블의 크기가 감소한다.
2) 복수의 테이블로 분할이 불리한 경우
서브 타입 구분 없이 데이터를 처리하는 경우에 UNION이 발생할 수 있다.
처리 속도 감소가 발생할 가능성이 높다.
트랜젝션을 처리하는 경우 다수 테이블을 처리하는 경우가 자주 발생한다.
복잡한 처리를 하는 SQL의 통합이 어렵다.
부분 범위에 대한 처리가 곤란해진다.
여러 테이블을 통합한 경우 뷰로 조회만 가능하다.
UID의 유지관리가 어렵다
(다) 개별 타입 기준 변환
슈퍼 타입과 서브 타입을 각각 테이블로 변환하는 것이다. 슈퍼 타입과 서브 타입
각각의 테이블 사이에는 1:1 관계가 형성된다.
1) 개별 타입 기준 테이블 변환을 사용하는 경우
- 전체 데이터에 대한 처리가 자주 발생하는 경우 사용한다.
- 서브 타입 처리가 대부분 독립적으로 발생하는 경우 사용한다.
- 통합하는 테이블의 칼럼 수가 지나치게 많은 경우 사용한다.
- 서브 타입 칼럼 수가 다수인 경우 사용한다.
- 트랜잭션이 주로 슈퍼 타입에서 발생하는 경우 사용한다.
- 슈퍼 타입에서 범위가 넓은 처리가 빈번하게 발생하여 단일 테이블 클러스
터링이 필요한 경우 사용한다.
2. 속성 & 칼럼 변환
속성이나 관계를 물리 데이터 모델 객체로 변환하여 나타나는 데이터의 실제 저장 형태,
예외 사항이 발생하는 경우 등에 대한 파악을 용이하게 하기 위해 사례 데이터 표의 작성
하는 것도 좋은 방법이다.
(1) 일반 속성 변환

51
(2) Primary UID 기본 키 변환
논리 모델링에서의 Primary UID는 물리 모델링에서는 기본 키로 생성된다. DDL에서는
오브젝트가 생성되어 기본 키 제약 조건의 속성을 갖는다.
(3) Primary UID(관계의 UID Bar) 기본 키 변환
Primary UID의 속성 중에는 해당 엔티티에서 생성된 속성도 존재하지만 다른 엔티티
와의 관계로 인해 생성되는 UID 속성도 존재할 수 있다. 이러한 관계 속성 UID의 변
환은 일반적인 속성 UID 변환과는 차이가 있다.
(4) Secondary(Alternate) UID 유니크 키 변환
논리 모델링에서 정의된 Secondary UID 및 Alternate Key들은 해당 엔티티와 상대 엔
티티의 선택적 관계를 갖는데 중요한 역할을 한다. 이러한 Secondary UID들은 물리 모
델에서는 유니크 키로 생성된다.
3. 관계 변환
(1) 1:M 변환
논리 데이터 모델의 관계에서 가장 보편적 형태의 관계이며, M 측의 관계 칼럼에 선
택사양이 결정되게 된다.
(2) 1:1 변환
논리 데이터 모델에서 1:1 관계는 일반적이지 않은 형태의 관계로 1:1 관계를 물리 모
델링에서 변환하는 과정은 관계의 기수성(Optionality)으로 인해 다른 방법이 적용된다.
양측 모두 Optional인 관계의 경우에는 상대적으로 자주 사용되는 테이블이 외래 키를
포함하는 것이 유리하다.
(3) 1:M 순환 관계 변환
일반적으로 데이터 계층 구조의 표현에 주로 사용하는 관계의 형태로 특성상 최상위
관계 속성은 항상 Optional의 형태를 보여야 한다. 그러나 경우에 따라 최상위 관계에
특정 값을 설정하는 경우도 있다.
(4) 베타적 관계 변환
실제 데이터 환경에서는 빈번하게 등장하는 논리 데이터 모델의 배타적 관계 모델은
물리 모델링에서 생성하는 방법이 일반적인 관계 변환 방법과는 차이가 있다.
(가) 외래 키(Foreign Key) 분리
관계별로 관계 칼럼을 생성하는 방법으로 실제 외래 키의 제약 조건(Foreign Key
Constraints)이 생성 가능하다는 장점이 있으나 키 칼럼들이 각각 Optional의 형태여
야 한다. 또한 체크 제약 조건(Check Constraints)의 추가적 생성이 필요하다.
(나) 외래 키 결합
관계들을 하나의 관계 칼럼으로 통합 생성하는 방법으로 실제 외래 키 제약 조건

52
의 생성은 불가능 하고 다수의 관계를 선별하여 구분하기 위한별도의 칼럼이 필요
하다.
4. 관리 목적의 칼럼의 추가
논리 모델링에서는 필요가 없으나 관리 또는 데이터베이스를 이용하는 프로그래밍의 수행
속도를 향상을 위해 추가되는 테이블이나 칼럼으로 관리상 필요한 데이터를 등록한 일자,
시스템 번호 등을 의미란다.
5. 데이터 타입 선택
물리 모델링에서 자주 발생하는 문제 중 하나가 칼럼 데이터 형식 설정의 오류로 인해 발
생한다. 데이터 형식을 설정하는 것은 논리 모델링에서 정의된 논리적인 데이터 타입(정
보 타입: Information Type)을 물리적인 DBMS 특성과 성능의 고려를 통해 최적 데이터
타입을 선택하는 작업이다.
주요 타입은 문자 타입 (Character Data Types), 숫자 타입 (Numeric Types), 날짜 타입
(Datetime Types)으로 구분할 수 있다.
6. 데이터 표준 적용
논리 데이터 모델링의 산출물을 물리 데이터 모델링에서 변환하는 경우 필수적으로 각각
의 대상에 대한 이름을 생성하게 된다. 이러한 이름의 변환 과정에서 데이터베이스의 활
용 및 관리를 고려하여 전사적으로 사전에 수립된 데이터 표준을 준수하게 된다. 이러한
데이터 표준에는 표준 용어, 표준 도메인, 표준 명명 규칙 등이 존재한다.
(1) 데이터 표준의 적용 대상
물리 데이터 모델에서의 데이터 표준화는 다음과 같은 객체를 대상으로 수행하게 된
다.
(가) 데이터베이스(Database)
테이블의 집합으로 통합 모델링 단계의 주제 영역이나 애플리케이션 모델링 단계
의 업무 영역에 대응되는 오브젝트이다.
(나) 스토리지 그룹(Storage Group)
하나의 그룹으로 물리적인 디스크(Disk)를 정의한 것이며 테이블스페이스, 인덱스 스
페이스 등이 생성되는 경우 스토리지 그룹명을 지정하여 물리적인 영역을 할당 한다.
(다) 테이블스페이스
테이블이 생성되는 물리적인 영역이며, 하나의 테이블 스페이스에 하나 또는 그 이
상의 테이블을 저장할 수 있다.
(라) 테이블
논리 설계 단계의 엔터티에 대응하는 객체이다.

53
(마) 칼럼
논리 설계 단계의 속성에 대응하는 객체이다.
(바) 인덱스
기본 키(Primary Key), 외래 키(Foreign Key)등을 대상으로 하는 대표적인 색인 데이
터로 테이블에서 특정 조건의 데이터를 효율적으로 검색하는 것을 목적으로 한다.
(사) 뷰
테이블을 재 정의하여 특정 사용자만 접근이 가능하도록할 수 있다.
물리적으로 테이블의 특정 칼럼이나 로우를 뷰로 정의한다.
(2) 데이터 표준 적용 방법
대표적으로 명명 규칙과 표준 용어 사전에 의한 두 가지 방법으로 나뉠 수 있으며, 일
반적으로 실제 적용하는 경우에는 두 가지의 방법을 함께 사용한다.
(가) 명명 규칙의 활용
테이블명의 변환시 엔터티 한글명과 동일한 용어를 사용하면서 해당 용어를 영
문명으로 전환한다.
영문명은 영문 약어를 사용하며, 표준 용어 사전에 등록된 표준 영문 약어를 참
조한다.
테이블의 명명 순서는 업무 영역, 주제어 수식어, 주제어, 분류어 수식어, 분류어,
접미사의 순서로 적용한다.
(나) 표준 용어 사전의 활용
모든 객체명과 객체별 데이터 타입, 길이 등의 명칭과 속성정보의 표준을 전사관점
에서 사전에 정의해 놓고 적용하는 방식이다.

54
수행 내용 / 테이블 기술서의 작성하기
재료·자료
Ÿ
시스템 조사 분석서, 물리 데이터베이스 설계서 또는 관련 자료
기기(장비 ・ 공구)
Ÿ
문서 작성 도구, 컴퓨터, 데이터베이스 운영 장비, 데이터베이스 프로그램, SQL 프로그램
수행 순서
논리 데이터베이스에서 물리 데이터베이스로 전환한다.
1. 관계형 데이터베이스 요소로 전환하기
2. 서브 타입 변환(Transformation)하기
(1) 슈퍼 타입 기준 테이블 변환하기
서브 타입을 슈퍼 타입에 통합하여 하나의 테이블로 만들며, 통합된 테이블에는
모든 서브 타입의 데이터를 포함해야 한다.
주로 서브 타입에 적은 양의 속성이나 관계를 가진 경우에 적용된다(지식 참조)
(가) 슈퍼 타입으로 테이블 명칭을 부여한다.
(나) 서브 타입의 구분이 가능하도록 칼럼을 추가한다.
(다) 슈퍼 타입의 속성을 칼럼명으로 명명한다.
(라) 서브 타입의 속성을 칼럼명으로 명명한다.
(마) 외래 키 (Foreign Key)를 적용하여 슈퍼 타입의 관계를 설정 한다.
(바) 외래 키 (Foreign Key)를 적용하여 서브 타입의 관계를 설정 한다.
(2) 서브 타입 기준 테이블 변환하기
슈퍼 타입 속성들을 각각의 서브 타입에 추가하여 각각의 서브 타입마다 하나의
테이블로 만든다. 분할된 테이블에는 서브 타입의 데이터만 포함돼야 하며, 주로
서브 타입에 많은 양의 속성이나 관계를 가진 경우에 적용된다.
(가) 서브 타입마다 테이블 명칭을 부여한다.
(나) 서브 타입의 속성을 칼럼명으로 한다.
(다) 테이블마다 슈퍼 타입의 속성을 칼럼으로 한다.
55
(라) 서브 타입마다 해당되는 관계들을 FK로 한다.
(마) 테이블마다 슈퍼 타입의 관계를 FK로 한다.
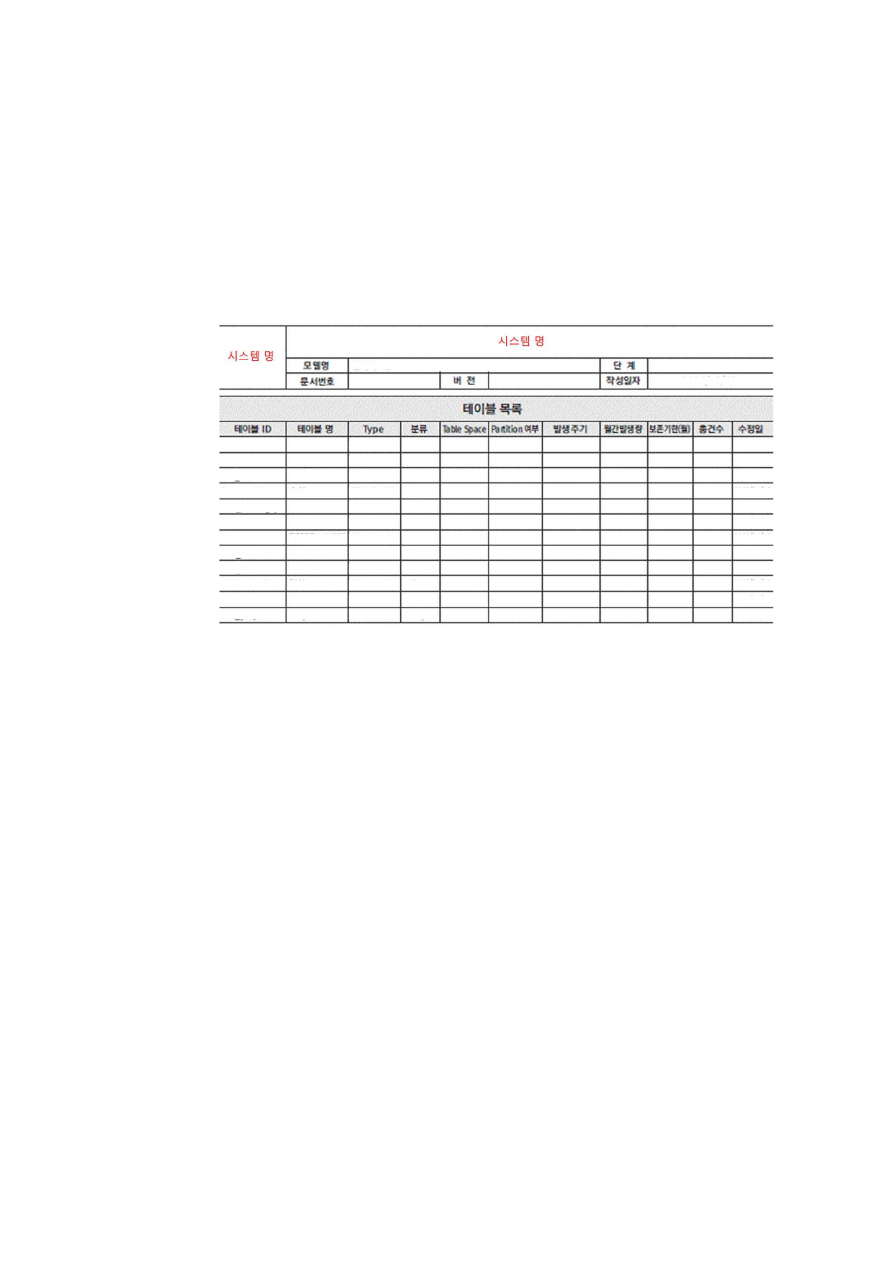
3. 테이블 목록 정의서 작성하기
엔터티를 테이블로 변환하는 과정이 완료되면 테이블 목록 정의서를 작성한다. 테이
블 목록 정의서는 줄여서 테이블 목록이라 부르기도 하며, 전체 테이블이 목록으로
요약 관리되어야 한다.
[그림 3-1] 테이블 목록 정의 예시
속성 및 칼럼을 변환한다.
1. 일반속성 변환하기
(1) 엔터티에 있는 각각의 속성들에 대한 칼럼명을 사례 데이터 표의 칼럼명 란에 기
록한다.
(2) 칼럼의 명칭은 속성의 명칭과 반드시 일치할 필요는 없으나 프로그래머와 사용자
의 혼동을 피하기위해 가능한 표준화된 약어를 사용한다.
(3) 표준화된 약어의 사용은 SQL 해독 시간을 감소시킨다.
(4) SSQL의 예약어(reserved word)의 사용을 피한다.
(5) 가급적 칼럼 명칭은 짧은 것이 좋으며, 짧은 명칭은 개발자의 생산성에 긍정적인
영향을 준다.
(6) 필수 입력 속성은 Null s/Unique 란에 NN을 표시한다.
(7) 실제 테이블에 대한 설계를 검증하기 위한 목적으로 가능하다면 표본 데이터를
입력시킨다.
2. Primary UID 기본 키(Primary Key) 변환하기
(1) 사례 데이터 표의 키 형태 란에 엔터티의 Primary UID에 속하는 모든 속성에 PK

56
를 표시한다.
(2) PK로 표시된 모든 칼럼은 Null s/Unique 란에 반드시 NN,U로 표시되어야 한다.
(3) 여러 개의 칼럼으로 UID가 구성되어 있는 경우는 각각의 칼럼에 NN,U1을 표시한다.
(4) 또 다른 Unique Key(Secondary UID)가 있다면 U2로 표시한다.
3. Primary UID(관계의 UID Bar) 기본 키(Primary Key) 변환 / Secondary (Alternate) UID
Unique Key 변환하기
(1) 테이블에 외래 키 칼럼을 포함시킨다
(2) PK의 일부분으로 표시한다.
Null s/Unique 란에 각각 NN, U1을 표시
키 형태란에 기본 키, 외래 키를 표시
여러 UID BAR가 있는 경우는 (PK, FK1), (PK, FK2), …
여러 칼럼으로 구성된 경우 PK,FK1을 각각 표시
(3) 추가된 FK 칼럼에 표본 데이터를 추가한다.
4. 테이블 정의서 작성하기
기본적인 테이블 변환, 칼럼 변환 작업이 완성되면 테이블 정의서를 생성한다.
관계를 변환한다.
1. 1:M 관계 변환하기
(1) 1(One) 에 있는 PK를 M(Many)의 FK로 변환한다.
FK의 명칭 결정
키 형태 란에 FK 표시
Null s/Unique 란에 NN 표시(Must Be 관계시)
필수 관계가 아닌 경우에는 NN를 체크하지 않는다.
(2) 표본 데이터를 추가한다.
(3) UID BAR 가 있는 경우는 전단계에서 실시한다.
2. 1:1 관계 변환하기
(1) Mandatory 반대쪽에 있는 테이블의 기본 키를 Mandatory 쪽 테이블의 외래 키로
변환한다.
(2) NN 표시를 한다.
3. 1:M 순환 관계 변환하기
(1) 해당 테이블 내에 외래 키 칼럼을 추가한다. 외래 키는 같은 테이블 내의 다른
로우의 기본 키 칼럼을 참조하게 된다.

57
(2) 외래 키 칼럼 명칭은 가능한한 관계 명칭을 반영한다. 외래 키는 결코 NN(Not
Nul ) 이 될 수 없다.
4. 베타적 관계 변환하기
(1) 외래 키(Foreign Key) 분리
(2) 외래 키 결합
5. 개별 테이블에 대한 테이블 기술서 작성하기
[그림 3-2] 테이블 기술서 예시
58
학습 3
교수 ‧ 학습 방법
교수 방법
• 논리데이터베이스 모델링의 산출물과 기존 데이터베이스 구조의 고려하여 변환관계에 대해
교육한다.
• 앞서 정의된 데이터베이스 구성 요소에 대한 정의 결과를 충분히 숙지하여 교육한다.
• 사전에 데이터용어 사전에 대해 충분히 숙지하여 표준화를 준수 할수 있도록 학습자를 유도하여
교육한다.
• 논리 모델링의 결과 즉 산출물이 확보되어 있다면, 본 물리 모델의 교육 내용과 관련 사항을
리스트화 하여, 반드시 학습자에 설명한다.
• 교육상에 발생하는 산출물은 대부분 학습자가 사용하는 데이터베이스나 학습자가 속한 조직
및 업무에 따라 상이하게 달라질 수 있다. 따라서 형식보다 산출물에 포함되는 내용의 의미와
역할 등을 중심으로 설명한다.
• 교수자는 반드시 교육내용에 산출물에 대한 작업이 필요한 경우 해당 학습자가 업무중 주로
사용하는 데이터베이스 프로그램의 특성이 반영되거나 소속된 조직에서 현재 사용되는 형태의
산출물 양식을 참고하여 교육을 수행한다.
학습 방법
• 기존 학습자가 사용하는 데이터베이스의 구조와 논리 데이터베이스 모델링 산출물의 결과를
고려하면 변환에 대한 이해와 활용이 용이하다.
• 표준화를 보장할 수 있도록 데이터용어 사전을 변환에 대한 학습에 적극 참조한다.
• 테이블 기술서는 기존 사용 양식이 있다면 준수하고 없다면 테이블 구성정보에 대해 상세히
정의하여 작성한다.
• 학습자는 교육내용상 제시되는 산출물이나 참고 자료의 형태가 본인이 주로 사용하는 데이터베
이스 프로그램이나 소속된 조직의 업무 양식과 다를 수 있음을 인지하고 형식보다 포함된 속성의
의미와 필요성을 이해해야 한다.
59
학습 3
평 가
평가 준거
• 평가자는 피평가자가 수행 준거 및 평가 내용에 제시되어 있는 내용을 성공적으로 수행할 수
있는지를 평가해야 한다.
• 평가자는 다음 사항을 평가해야 한다.
학습 내용
평가 항목
성취수준
상
중
하
물리 E-R 다이
어그램 작성
- 논리 데이터베이스 설계에서 엔티티, 속성, 주식별
자, 외래식별자를 각각 테이블, 칼럼, 기본 키, 외래
키로 변환하여 표현할 수 있다.
- 물리 E-R 다이어그램 작성 툴로 도출된 테이블, 칼
럼, 키 값을 도식화하고 설계서를 작성할 수 있다.
- 엔티티명, 속성 명에 대한 Data dictionary(용어 사전)
정의하고, 테이블명, 칼럼명, 키 종류, Nul 값 허용여
부 정보를 기준으로 테이블 기술서를 작성할 수 있
다.
평가 방법
• 서술형 시험
학습 내용
평가 항목
성취수준
상
중
하
물리 E-R 다이
어그램 작성
- 논리 데이터베이스 설계에서 변환되는 용어에 대한
이해의 정도를 평가
- 물리 데이터베이스 설계에 대한 표준화 적용 및 테
이블 정의를 할 수 있는가를 평가
• 포트폴리오
학습 내용
평가 항목
성취수준
상
중
하
물리 E-R 다이
어그램 작성
- 테이블 기술서를 작성할 수 있는 가를 평가
60
• 평가자 체크리스트
학습 내용
평가 항목
성취수준
상
중
하
물리 E-R 다이
어그램 작성
- 논리 데이터베이스 설계에서 엔티티, 속성, 주식별
자, 외래식별자를 각각 테이블, 칼럼, 기본 키, 외래
키로 변환하여 표현할 수 있는가를 평가
- 물리 E-R 다이어그램 작성 툴로 도출된 테이블, 칼
럼, 키 값을 도식화하고 설계서를 작성할 수 있는가
를 평가
- 엔티티명, 속성 명에 대한 Data dictionary(용어 사전)
정의하고, 테이블명, 칼럼명, 키 종류, Nul 값 허용여
부 정보를 기준으로 테이블 기술서를 작성할 수 있
는가를 평가
피 드 백
1. 서술형 시험
- 논리 데이터베이스 설계에서 변환되는 용어를 이해하고 있는가를 확인하여 부족한 부분
을 숙지하도록 한다.
- 물리 데이터베이스 설계에 대한 표준화 적용 및 테이블 정의에 대해 이해하고 있는가를
확인하여 부족한 부분을 숙지하도록 한다.
2. 작업 포트폴리오
- 테이블 기술서를 작성할 수 있는 가를 확인한다.
3. 체크리스트를 통한 관찰
- 논리 데이터베이스 설계에서 변환하여 표현할 수 있는가를 확인하여 부족한 부분을 보충
하도록 한다.
- 물리 E-R 다이어그램 작성 툴로 도출된 결과를 도식화하고 설계서를 작성할 수 있는가를
확인하여 부족한 부분을 보충하도록 한다.
- 엔티티명, 속성 명에 대한 Data dictionary(용어 사전) 정의하고, 테이블 기술서를 작성할
수 있는가를 확인하여 부족한 부분을 보충하도록 한다.

61
학습 1
물리 속성 조사 분석하기
학습 2
데이터베이스 물리 속성 설계하기
학습 3
물리 E-R 다이어그램 작성하기
학습 4 데이터베이스 반정규화하기
학습 5
물리 데이터 모델 품질 검토하기
4-1. 반정규화 수행
학습 목표
• 시스템의 성능을 고려한 기존 설계를 재구성하기 위해 반정규화 대상을 조사하고,
선정할 수 있다.
• 테이블간의 조인을 줄이기 위한 칼럼 반정규화, 정규화에서 나눈 테이블을 하나의
테이블로 통합, 하나의 테이블을 여러 개 테이블로 분리, 요약 테이블을 생성의 방법
으로 반정규화를 수행할 수 있다.
• 반정규화에 따른 영향도를 조사하여 적절한 조치를 하고, 반정규화가 적용된 물리 데이터베이스
설계서를 작성할 수 있다.
필요 지식 /
반정규화
논리 모델링에서 수행된 정규화 작업을 통해 데이터 모델은 데이터의 중복의 최소화와 데
이터의 일관성, 정확성, 안정성 등을 보장하는 데이터 구조를 완성할 수 있다.
반정규화는 정규화된 데이터 모델이 시스템의 성능 향상, 개발 과정의 편의성, 운영의 단
순화를 목적으로 수행되는 의도적인 정규화 원칙 위배 행위를 의미한다.
반정규화된 데이터 구조는 성능 향상과 관리의 효율성이 증가하는 장점이 있으나, 데이터
의 일관성 및 정합성 저하와 유지를 위한 비용이별도로 발생하여 과도할 경우 오히려 성
능에도 나쁜 영향을 미칠 수 있다.
따라서 반정규화를 위해서는 사전에 데이터 모델 각각의 구성 요소인 엔터티, 속성, 관계
에 대해 데이터의 일관성과 무결성을 우선으로 할지 데이터베이스의 성능과 단순화에 우
선순위를 둘 것인지를 비교하여 조정하는 과정이 매우 중요하며, 따라서 반정규화 과정의
효과적인 수행에는 다양한 경험이 보유한 작업자가 유리하다.
1. 테이블 분할
테이블 분할은 테이블을 수직 또는 수평으로 분할하는 것으로 파티셔닝이라고 한다.

62
테이블 분할을 의미하는 파티셔닝은 데이터베이스 디자인 단계에서의 데이터 저장 방식을
의미하는 파티셔닝과는 다른 용어 개념이다.
(1) 수평 분할(Horizontal Partitioning)
테이블 분할에 레코드(Record)를 기준으로 활용하는 것이다.
(2) 수직 분할 (Vertical Partitioning)
하나의 테이블이 가지는 칼럼의 개수가 증가하는 경우 수직 분할을 활용한다.
대표적으로 다음과 같은 경우에 수직 분할이 이뤄진다.
(가) 갱신 위주의 칼럼 수직 분할
갱신 위주의 칼럼들을 분할하는 이유는 데이터를 갱신하는 작업이 일어날 때 업데
이트하려는 레코드(Record), 즉 레코드에 잠금(Locking)을 수행하기 때문이다. 잠금
은 데이터의 무결성을 유지를 위한 수단으로 특정 프로세스가 특정 데이터 값을
변경하려고할 때 변경 작업의 완료까지는 여타 프로세스가 해당 데이터 값의 변경
금지하는 것이다.
1) DBMS 또는 버전별 적용 검토
일부 DBMS의 경우 잠금의 작용이 레코드 전체에 걸리는 경우가 있기 때문에
업데이트 완료까지 레코드의 사용이 불가한 요인으로 작용한 된다. 즉, 칼럼에
대한 갱신 위주의 몇몇 작업이 나머지 조회 위주의 적업을 방해하는 것이다. 이
러한 경우에는 갱신 위주의 칼럼들을 수직 분할하여 사용하는 방법이 데이터
사용의 효율성을 향상에 도움이 된다.
(나) 조회 빈도가 높은 칼럼 분할
특정 칼럼의 조회 빈도가 높다면 해당 칼럼을 분리하여 별도의 테이블로 관리하면
조회 쿼리의 성능을 높일 수 있다.
즉 특정 테이블에 칼럼 수가 매우 많지만 조회 빈도가 소수의 칼럼들에 집중된다
면 조회 빈도가 높은 칼럼으로 이루어진 테이블의 생성을 통해 실제 물리적인 I/O
의 양을 감소시켜 데이터 액세스 성능을 향상시킬 수 있다.
1) 물리적인 DBMS 메커니즘 고려
DBMS는 액세스하고자 하는 데이터를 초기에 물리적인 데이터 파일에서 메모리
로 읽어 들이는 과정을 수행한다. 이렇게 읽혀진 데이터는 바로 지워지는 것이
아니라 일정기간 메모리에 남아있게 된다. 이러한 메커니즘 관점에서도 알 수
있듯 칼럼 수가 적은 테이블을 자주 읽는 작업을 많이 한다면 초기 데이터를
메모리로 적재하는 비용을 절약할 수 있고, 메모리에 상대적으로 오래 저장될
수 있기 때문에 데이터 재사용성을 향상시키는 효과를 얻을 수 있다.
(다) 크기가 매우 큰 칼럼의 경우 분할
크기가 아주 큰 칼럼이 있는 경우 분할이 발생하는 대부분의 경우는 칼럼의 크기
보다는 특정한 데이터 형식이 원인인 경우가 대부분이다.

63
문자열을 저장하기 위해 지원하는 데이터 타입은 2GB 이상 저장할 수 있고, 이미
지 데이터를 저장할 수도 있다. 이렇듯 텍스트 및 이미지 등의 LOB(Large Objects)
데이터 형식을 지원하는 방법은 DBMS마다 조금씩 차이는 있지만, 테이블의 칼럼에
텍스트 및 이미지 데이터가 포함될 때는 일반적으로 성능이 저하될 가능성 증가한
다. 이것은 백업, 복원과 같은 관리나 프로그래밍과 같은 개발 부분에서 다양한 성
능 저하 요인으로 작용할 수 있다는 것이다. 따라서 이러한 데이터 형식의 경우 분
리할 수 있다.
(라) 특정 칼럼에 보안을 적용해야 하는 경우
일반적으로 DBMS에서는 테이블이나 뷰와 같은 객체들에 대해서는 SELECT, UPDATE,
DELETE 등과 같은 권한 제어 기능을 제공하고 있다. 반면 테이블 내의 칼럼에 대
해서는 테이블과 같은 권한(Permission) 제어 기능을 제공하지 않는 것이 일반적이
다. 따라서 칼럼에 대해 권한을 제어하기 위해 보안 적용 대상 칼럼을 분리해별도
의 테이블로 생성하여 권한 제어의 목적으로 수직 분할을 할 수 있다.
2. 중복 테이블 생성
데이터베이스를 활용하다보면 대량의 데이터들에 대해 집계함수(Group By, Sum 등)를 사
용하여 실시간 통계정보를 계산하는 경우가 자주 발생한다. 그러나 대부분의 경우 이러한
대상 데이터는 매우 많은 양인 경우가 대부분이며, 단일 테이블 보다는 다수의 테이블에
서 필요한 데이터를 추출하여 활용하는 경우가 대부분이다. 이러한 작업의 효과적인 수행
을 위해별도의 통계 테이블을 두거나 중복 테이블을 추가할 수 있다.
3. 중복 칼럼 생성
논리 모델링 과정에서는 정규화를 통하여 중복 칼럼을 최대한 제거하는 작업을 수행한다.
중복 데이터 제거 작업의 목적은 다양하게 존재하지만 가장 큰 이유 중에 하나는 데이터
의 정합성을 보장하기 위함이다. 그런데 물리 데이터 모델링 과정에서 이러한 정규화를
어기면서 다시 데이터의 중복(중복 칼럼 생성)을 수행하곤 한다.
수행 내용 / 반정규화 수행하기
재료·자료
Ÿ
시스템 조사 분석서, 물리 데이터베이스 설계서 또는 관련 자료

64
기기(장비 ・ 공구)
Ÿ
컴퓨터, 프린터, 문서 작성 도구
안전 ・ 유의 사항
Ÿ
반정규화와 정규화의 장점과 단점을 파악하고 우선순위에 따른 적절한 조절이 필요하다.
Ÿ
반정규화가 미치는 영향에 대한 결과를 반드시 고려해야 한다.
수행 순서
정규화와 반정규화에 대한 대상의 우선순위와 대안, 적절성 등을 고려한다.
반정규화를 준비한다.
1. 반정규화 대상 조사하기
범위 처리 빈도수, 대량의 범위 처리 조사, 통계성 프로세스 조사, 테이블 조인 개수
등을 조사 한다.
2. 대안 적용에 대한 검토하기
뷰, 클러스터링, 인덱스, 응용 어플리케이션 등의 적용 및 조정을 통한 대안 적용 여
부를 검토한다.
반정규화의 적용한다.
1. 테이블의 반정규화하기
(1) 수평 분할(Horizontal Partitioning)
(가) 레코드(Record)를 기준으로 테이블을 분할하는 것을 말한다.
(나) 하나의 테이블에 데이터가 너무 많이 있고, 레코드 중에서 특정한 덩어리의
범위만을 주로 액세스 하는 경우에 사용한다.
(다) 분할된 각각의 테이블은 서로 다른 디스크에 위치시켜 물리적인 디스크의 효
용성을 극대화할 수 있다.
(라) 이러한 수평 테이블의 분할은 DBMS 차원에서 제공하고 있다. 특히 분할의
방법 다양하게 제공하고 있는 추세이다. 분할의 대표적인 방법으로는 범위
분할, 해시 분할, 복합 분할 등의 기법이 사용된다.
(2) 수직 분할(Vertical Partitioning)
하나의 테이블이 가지는 레코드의 개수가 많아서 수평 분할을 한다면 수직 분할

65
은 하나의 테이블이 가지는 칼럼의 개수가 많아지기 때문에 일어난다.
조회 위주의 칼럼과 갱신 위주의 칼럼으로 나뉘는 경우
특별히 자주 조회되는 칼럼이 있는 경우
특정 칼럼 크기가 아주 큰 경우
특정 칼럼에 보안을 적용해야 하는 경우
2. 중복 테이블 생성하기
다음과 같은 경우 중복 테이블 생성을 고려한다.
정규화에 충실하면 종속성, 활용성은 향상되나 수행 속도 증가가 발생하는 경우 고
려한다.
많은 범위를 자주 처리해야 하는 경우에 고려한다.
특정 범위의 데이터만 자주 처리되는 경우에 고려한다.
처리 범위를 줄이지 않고는 수행 속도를 개선할 수 없는 경우에 고려한다.
요약 자료만 주로 요구되는 경우에 고려한다.
추가된 테이블의 처리를 위한 오버헤드를 고려하여 결정한다.
인덱스의 조정이나 부분 범위 처리로 유도, 클러스터링을 이용하여 해결할 수 있는
지를 철저히 검토한 후 결정한다.
(1) 중복 테이블 유형
중복 테이블에는 다양한 유형이 존재한다. 집계, 진행 테이블 추가를 검토할 수
있는 상황에 대한 예를 들면 다음과 같다.
(가) 집계(통계) 테이블 추가하기
Ÿ
집계 테이블 유형을 확인한다.
- 단일 테이블의 GROUP BY
- 여러 테이블의 조인 GROUP BY
Ÿ
집계 테이블 생성시 유의 사항을 숙지한다.
- 로우 수와 활용도를 분석하고 시뮬레이션을 통해서 그 효용성에 대한 면
밀한 검토가 선행되어야 한다.
- 집계 테이블에 단일 테이블 클러스터링을 한다면 집계 레벨을 좀 더 낮춰
활용도를 높일 수 있는지를 검토해야 한다.
- 클러스터링, 결합 인덱스, 고단위 SQL을 활용하면 굳이 집계 테이블 없이도
- 양호한 수행 속도를 낼 수 있다. 이러한 부분도 사전 검토되어야 한다.
- 집계 테이블을 다시 집계, 조인하면 추출할 수 있는지를 검토하여 지나친
집계 테이블을 만들지 않는 것이 좋다.
- 추가된 집계 테이블을 기존 응용 프로그램이 이용할 수 있는지를 찾아 보
정시키는 노력이 필요하다.
- 데이터베이스 트리거의 오버헤드에 주의하고 데이터의 일관성 보장에 유

66
의하여야 한다. 즉 집계 테이블과 원본 데이터는 일관성 유지가 매우 중
요하다.
(나) 진행 테이블 추가하기
Ÿ
진행 테이블 추가 상황을 확인한다.
- 여러 테이블의 조인이 빈번히 발생하며 처리 범위도 넓은 경우
- M:M 관계가 포함된 처리의 과정을 추적, 관리하는 경우
- 검색 조건이 여러 테이블에 걸쳐 다양하게 사용되며 복잡하고 처리량이
많은 경우
Ÿ
진행 테이블 생성시 유의 사항을 확인한다.
- 데이터량이 적절하고 활용도가 좋아지도록 기본 키를 선정한다.
- 필요에 따라 적절한 추출(Derived) 칼럼을 추가하여 집계 테이블의 역할도
하는 다목적 테이블을 구상한다.
- 다중 테이블 클러스터링이나 조인 SQL을 적절히 이용하면 굳이 진행 테이
블을 만들지 않아도 양호한 수행 속도를 낼 수 있는 경우가 많다.
3. 중복 칼럼의 생성하기
(1) 중복 칼럼 생성 상황을 확인한다.
빈번하게 조인을 일으키는 칼럼에 대해서 고려해 볼 수 있다.
조인의 범위가 다량인 경우를 온라인화해야 하는 경우처럼 속도가 중요한 칼럼
에 대해서는 중복 칼럼을 고려할 수 있다.
액세스의 조건으로 자주 사용되는 칼럼에 대해서 고려해 볼 수 있다.
자주 사용되는 액세스 조건이 다른 테이블에 분산되어 있어 상세한 조건 부여
에도 불구하고 액세스 범위를 줄이지 못하는 경우에 자주 사용되는 조건들을
하나의 테이블로 모아서 조건의 변별성을 극대화할 수 있다.
복사된 칼럼의 도메인은 원본 칼럼과 동일하게 해야 한다. 이것은 데이터의 일
관성을 위해서 필수적인 사항이다.
접근 경로의 단축을 위해서 부모 테이블의 칼럼을 자식 테이블에 중복시킬 수
있다.
상위 레벨의 테이블에 집계된 칼럼을 추가(M:1 관계)할 수 있다. 즉, 집계 칼럼
을 추가한다.
하위 레벨의 테이블로 중복 칼럼을 복사(M:1 관계)할 수 있다.
연산된 결과를 주로 사용하는 경우에도 미리 연산을 하여 중복 칼럼을 생성할
수 있다.
여러 칼럼들의 수 밖에 없는 값이 검색의 조건으로 사용되는 경우에는 연산의
결과를 중복 칼럼으로 생성할 수 있다.

67
여러 개의 로우로 구성되는 값을 하나의 로우에 나열하는 경우이다. 즉 로우로
관리하던 데이터를 칼럼으로 관리하는 경우이다.
기본 키의 칼럼이 길거나 여러 개의 칼럼으로 구성되어 있는 경우 인위적인 기
본 키를 추가할 수 있다.
(2) 중복 칼럼 생성 유의 사항을 확인한다.
다중 테이블 클러스터링으로 해결할 수 있는지 검토한다.
SQL GROUP 함수 이용하여 처리할 수 있는지 검토한다.
저장 공간의 지나친 낭비를 고려하여 적절한 대비책을 마련해야 한다.
반복 칼럼은 특별한 경우를 제외하고는 절대 사용할 필요가 없고, 있다면
sum(decode. ) 용법과 같은 SQL 기법 등을 활용하여 이러한 부분을 피할 수 있
도록 한다.
경우에 따라 상대 테이블의 ROWID를 복사하는 경우가 효과적일 때도 있다.
데이터의 일관성 보장에 유의해야 한다. 성능을 향상시키기 위해서 데이터의
일관성을 그르치는 일이 일어나서는 안된다.
칼럼의 중복이 지나치게 심하면 데이터 처리의 오버헤드가 발생하게 된다.
사용자나 프로그램은 반드시 원본 칼럼만 수정하는 것이 바람직하다.
일반적으로 수행 속도를 우려해서 지나치게 많은 중복 칼럼을 생성하고 있는
것이 현실이다. 가능하면 중복 칼럼을 적게 가져가는 것이 바람직하다.
클러스터링, 결합 인덱스, 적절한 SQL을 이용하면 특별한 경우를 제외하고는
거의 해결 가능하기 때문에 이 부분을 먼저 적극적으로 고려해 보는 것이 바람
직하다.
중복 칼럼을 이용하면 손쉽게 액세스 효율을 개선할 수 있으나 지나친 중복화
는 반드시 데이터 일관성 오류 발생의 개연성 증가 및 데이터 처리 오버헤드
증가라는 반대급부가 있다는 것을 염두 에 두고 수행해야 한다.
- JOIN, SUB-QUERY 액세스 경로의 최적화 방안을 보다 철저히 강구해야 한다.
수행 tip
Ÿ 반정규화 대상에 대한 정규화와 반정규화의 장
단점을 충분히 고려한다.
Ÿ 대안이 있다면 반정규화 보다 대안을 먼저 고려해
본다.
Ÿ
반정규화 시 각각의 유의 사항을 반드시 참조한다.
68
학습 4
교수 ‧ 학습 방법
교수 방법
• 논리 모델링의 결과 즉 산출물이 확보되어 있다면, 본 물리 모델의 교육 내용과 관련 사항을
리스트화 하여, 반드시 학습자에 설명한다.
• 학습자의 정규화와 반정규화의 이해 수준을 파악한다.
• 정규화와 반정규화의 장 단점을 비교하고, 반정규화의 목적을 명확하게 전달한다.
• 반정규화 대상의 대안을 함께 제시하고 설명한다.
• 교육상에 발생하는 산출물은 대부분 학습자가 사용하는 데이터베이스나 학습자가 속한 조직
및 업무에 따라 상이하게 달라질 수 있다. 따라서 형식보다 산출물에 포함되는 내용의 의미와
역할 등을 중심으로 설명한다.
• 교수자는 반드시 교육내용에 산출물에 대한 작업이 필요한 경우 해당 학습자가 업무중 주로
사용하는 데이터베이스 프로그램의 특성이 반영되거나 소속된 조직에서 현재 사용되는 형태의
산출물 양식을 참고하여 교육을 수행한다.
학습 방법
• 정규화와 반정규화의 특성과 차이에 대해 이해한다.
• 반정규화 대상의 대안을 항상 고려한다.
• 반정규화가 목적이 아님을 분명하게 인지한다.
• 학습자는 교육내용상 제시되는 산출물이나 참고 자료의 형태가 본인이 주로 사용하는 데이터베
이스 프로그램이나 소속된 조직의 업무 양식과 다를 수 있음을 인지하고 형식보다 포함된 속성의
의미와 필요성을 이해해야 한다.
69
학습 4
평 가
평가 준거
• 평가자는 피평가자가 수행 준거 및 평가 내용에 제시되어 있는 내용을 성공적으로 수행할 수
있는지를 평가해야 한다.
• 평가자는 다음 사항을 평가해야 한다.
학습 내용
평가 항목
성취수준
상
중
하
반정규화 수행
- 시스템의 성능을 고려한 기존 설계를 재구성하기 위
해 반정규화 대상을 조사하고, 선정할 수 있다.
- 테이블간의 조인을 줄이기 위한 칼럼 반정규화, 정
규화에서 나눈 테이블을 하나의 테이블로 통합, 하
나의 테이블을 여러 개 테이블로 분리, 요약 테이블
을 생성의 방법으로 반정규화를 수행할 수 있다.
- 반정규화에 따른 영향도를 조사하여 적절한 조치를
하고, 반정규화가 적용된 물리 데이터베이스 설계서
를 작성할 수 있다.
평가 방법
• 서술형 시험
학습 내용
평가 항목
성취수준
상
중
하
반정규화 수행
- 시스템의 성능을 고려한 기존 설계를 재구성하기 위
해 반정규화 대상을 조사하고, 선정하는 방법을 이
해하는 가를 평가.
- 테이블간의 조인을 줄이기 위한 칼럼 반정규화, 정
규화에서 나눈 테이블을 하나의 테이블로 통합, 하
나의 테이블을 여러 개 테이블로 분리, 요약 테이블
을 생성의 방법으로 반정규화를 수행하면서 필요한
특성과 대안에 대해 이해하는가를 평가.
- 반정규화에 따른 영향도를 조사하여 적절한 조치를
하고, 반정규화가 적용된 물리 데이터베이스 설계서
작성 등에 필요한 반정규화의 목적과 영향을 이해하
는 가를 평가.
70
• 포트폴리오
학습 내용
평가 항목
성취수준
상
중
하
반정규화 수행
- 번정규화가 적용된 물리데이터베이스 설계서 작성할
수 있는가를 평가
• 평가자 체크리스트
학습 내용
평가 항목
성취수준
상
중
하
반정규화 수행
- 정규화와 반정규화의 장단점과 특성, 대안의 이해
정도를 평가
- 대상에 적합한 반정규화 방법의 적용을할 수 있는
가를 평가
- 반정규화의 영향에 대한 이해도를 평가
피 드 백
1. 서술형 시험
- 반정규화 대상의 유형과 조사방법을 이해하는가를 확인하여 부족한 부분을 숙지하도록
한다.
- 정규화와 반정규화의 특성과 대안에 대해 이해하는가를 확인하여 부족한 부분을 숙지하
도록 한다.
- 반정규화의 목적과 영향을 이해하는가를 확인하여 부족한 부분을 숙지하도록 한다.
2. 작업 포트폴리오
- 물리데이터베이스 설계서에 반정규화를 적용할 수 있는 가를 확인한다.
3. 체크리스트를 통한 관찰
- 정규화와 반정규화의 장단점과 특성, 대안을 충분히 이해하고 있는가를 확인하여 부족한
부분을 보충하도록 한다.
- 대상에 적합한 반정규화 방법의 적용에 대해 이해하고 있는가를 확인하여 부족한 부분을
보충하도록 한다.
- 반정규화의 영향을 이해하고 있는가를 확인하여 부족한 부분을 보충하도록 한다.
71
학습 1
물리 속성 조사 분석하기
학습 2
데이터베이스 물리 속성 설계하기
학습 3
물리 E-R 다이어그램 작성하기
학습 4
데이터베이스 반정규화하기
학습 5 물리 데이터 모델 품질 검토하기
5-1. 물리데이터 모델 품질 점검
학습 목표
• 물리 데이터 모델에 대하여 정확성, 완전성, 준거성, 최신성, 일관성, 활용성의 품질
기준을 적용할 수 있다.
• 논리 데이터 모델과 물리 데이터 모델을 비교하여 테이블, 칼럼, 키, 오브젝트 구성
요소의 누락 여부와 일치성을 확인할 수 있다.
• 물리 데이터 모델의 품질 기준에 따라 테이블, 칼럼, 키에 대하여 데이터 표준화 준
수 여부를 확인하고 품질 검토 보고서를 작성할 수 있다.
필요 지식 /
물리 데이터 모델 품질 검토
물리 데이터 모델 설계가 완료되면 이를 데이터베이스 객체로 생성하고 개발 단계로 넘어
가기 전에 모델러를 비롯한 이해관계자들이 모여 물리 데이터 모델에 대한 리뷰 세션을
통해 작성된 데이터 모델의 품질을 검토하는 것이 바람직하다.
데이터 모델 검토는 개념 데이터 모델링, 논리 데이터 모델링, 물리 데이터 모델링 각각의
단계가 수행된 후 각각의 단계에서 작성된 모델에 대해 이루어져야 하지만, 특히 물리 데
이터 모델은 시스템 성능에 대해 직접적인 영향을 미치기 때문에 향후에 발생할 수 있는
성능 문제를 사전에 검토하여 최소화하는 노력이 절대적으로 필요하다.
논리 데이터 모델의 검토 시와 마찬가지로 물리 데이터 모델을 검토하기 위해서는 모든
이해관계자가 동의하는 검토 기준이 필요하며, 데이터아키텍처 정책 수립 시 DA원칙/표준
에 포함되어야할 중요한 사안이다.
기본적인 품질 검토 기준은 학습“데이터 품질 관리 이해 부분”에서 설명한 데이터 구조
의 관리 기준을 준용할 수 있다. 물리 데이터 모델 품질 검토의 목적은‘성능’과‘오류
예방’의 관점에서 생각해 볼 수 있으며, 이에 따라 물리 데이터 모델의 품질 기준도 조

72
직에 따라 혹은 업무 상황이나 여건에 따라 가감하거나 변형하여 사용하기도 한다.
1. 물리 데이터 모델 품질 기준 예시
일반적으로 사용되는 대표적인 기준 항목으로 구성된 물리 데이터 모델 품질 기준은 다음
과 같다.
(1) 정확성
데이터 모델이 표기법에 따라 정확하게 표현되었고, 업무 영역 또는 요구 사항이 정확
하게 반영되었음을 의미함
(가) 검토 예시
- 사용된 표기법에 따라 물리 데이터 모델이 정확하게 표현 되었는가
- 대상 업무영역의 업무 개념과 내용이 정확하게 표현 되었는가
- 요구 사항의 내용이 정확하게 반영 되었는가
- 업무규칙이 정확하게 표현/적용 되었는가
(2) 완전성
데이터 모델의 구성 요소를 정의하는데 있어서 누락을 최소화하고, 요구 사항 및 업무
영역 반영에 있어서 누락이 없음을 의미함
(가) 검토 예시
- 물리 데이터 모델 작성 항목의 충실성(완성도)
- 필요한 설명 항목(테이블/칼럼 설명 등)들의 작성 상태
- 물리 모델링 단계에서 결정해야할 항목들의 작성 상태(칼럼의 데이터 타입 및 길
이, Null 허용 여부, 서브 타입 변환, 배타관계 변환, PK, FK, 데이터 무결성 관련
제약사 항 등. 필요에 따라서는 저장 공간 지정, 테이블/인덱스 생성 관련 파라미
터 결정 사항 등까지도 포함)
- 요구 사항 반영 및 업무 영역 반영의 완전성: 목적하는 업무 영역을 기술(설계)한
논리 데이터 모델의 구성 요소(엔터티, 속성, 관계, 식별자 등)들이 누락없이 물
리 데이터 모델로 변환되어 정의된 정도 (단, 특별한 목적 에 의해 일부만 물리
데이터 모델로 변환될 수 있으며, 이 경우 목적이 명확해야함)
(3) 준거성
제반 준수 요건들이 누락 없이 정확하게 준수되었음을 의미함
(가) 검토 예시
- 데이터 표준, 표준화 규칙 등을 준수 하였는가
- 법적 요건을 준수 하였는가
- 법적 요건을 준수하기에 충분하도록 도메인이 정의 되었는가

73
(4) 최신성
데이터 모델이 현행 시스템의 최신 상태를 반영하고 있고, 이슈 사항들이 지체 없이
반영되고 있음을 의미
(가) 검토 예시
- 업무상의 변경이나 결정 사항 등이 시의 적절하게 반영되고 있는가
- 최근의 이슈 사항이 반영 되었는가
- 현행 데이터 모델은 현행 시스템과 일치 하는가
(5) 일관성
여러 영역에서 공통 사용되는 데이터 요소가 전사 수준에서한 번만 정의되고 이를 여
러 다른 영역에서 참조·활용되면서, 모델 표현상의 일관성을 유지하고 있음을 의미함
(가) 검토 예시
- 여러 주제영역에서 공통적으로 사용되는 엔터티는 일관성 있게 변환되었는가 (전
사 수준에서한 번만 정의되고 이를 여러 다른 영역에서 참조·활용한다는 의미
에서 통합성이라 하기도 함)
- 모델 표현상의 일관성을 유지하고 있는가
- 동일·유사 목적·용도의 칼럼들은 일관성 있게 정의되었는가
- 조인 대상 칼럼들은 일관성 있게 정의 되었는가
(6) 활용성
작성된 모델과 그 설명 내용이 이해관계자에게 의미를 충분하게 전달할 수 있으면서,
업무 변화 시에 설계 변경이 최소화되도록 유연하게 설계되어 있음을 의미
(가) 검토 예시
- 작성된 설명 내용이나 모델 표기 등이 사용자나 모델을 보는 사람에게 충분히
이해가될 수 있고, 모델의 작성 의도를 명확하게 이해할 수 있는가 (의사소통의
충분성)
- PK, UK 등의 칼럼 구성은 데이터 무결성을 보장하면서 데이터 액세스를 효율화
하기에 충분한가
- 논리 데이터 모델의 유연성이 물리 데이터 모델에도 반영되었는가 (오류가 적고
업무 변화에 유연하게 대응하여 데이터 구조의 변경이 최소화될 수 있는 설계
결과)
- 코드화 대상 칼럼에 대한 코드 정의는 업무 지원 및 적용에 충분한가
2. 물리 데이터 모델 품질 검토 체크리스트의 활용
물리 데이터 모델의 품질 검토 기준에 따라서 물리 데이터 모델에 정의된 테이블, 칼럼,
Key 구성, 무결성 제약 조건 등 물리 데이터 모델의 주요 구성 요소와 물리 데이터 모델

74
전반에 대한 체크리스트를 구성할 수 있으며, 이를 통해 물리 데이터 모델의 품질 검토를
보다 용이하게 수행할 수 있다.
수행 내용 / 물리 데이터 모델 품질 검토하기
재료·자료
Ÿ
데이터 아키텍처 원칙/표준화 관련 자료
Ÿ
데이터 품질 정책 자료
Ÿ
데이터 품질 진단자료
Ÿ
물리 데이터 모델 설계서 또는 관련 자료
기기(장비 ・ 공구)
Ÿ
컴퓨터, 프린터
Ÿ
문서 작성 도구
Ÿ
물리 데이터 모델 품질 검토 체크리스트
안전 ・ 유의 사항
Ÿ
물리 데이터 모델 품질 검토의 주요 목적은 ‘성능’과 ‘오류예방’이다. 따라서 데이터 품질
기준 및 정책이 수립되어 있는 경우에도 절대적으로 반영하기보다. 조직, 업무 상황 및 여건에
따라 유연성 있게 적용할 수 있어야 한다.
수행 순서
물리 데이터 모델 품질 기준 수립 및 체크리스트를 작성한다.
1. 데이터 품질 정책 및 기준 확인을 확인한다.
데이터 아키텍처의 품질 정책, 표준화, 데이터 품질 정책 및 기준 등의 품질 관련 자

75
료를 확인한다.
2. 물리 데이터 품질 기준 수립 및 체크리스트를 작성한다.
물리 데이터 모델의 특성을 반영한 품질 기준을 작성한다.
작성된 물리 데이터 품질 기준을 기반으로 물리 데이터 모델 품질 검토 체크리스트
를 작성한다.
(1) 품질 기준 예시를 확인한다.
정확성, 완전성, 준거성, 최신성, 일관성, 활용성
(2) 체크리스트 구성 항목 예시를 확인한다.
테이블, 칼럼, 키 등의 표준화 준수 여부 등
논리 데이터 모델과 물리 데이터 모델을 비교 분석한다.
1. 논리 데이터 모델과 물리 데이터 모델의 비교하기
논리 데이터베이스 모델 산출물(논리 ERD, 개체 관계 정의서 등)과 물리 데이터베이
스 모델 산출물(물리 데이터베이스 모델 설계서 등)의 비교 분석을 수행한다.
(1) 체크 항목을 확인한다.
테이블, 칼럼, 키, 오브젝트 구성 요소의 누락 여부와 일치성을 확인한다.
체크리스트 기반 각각의 단계별 모델러와 이해관계자 리뷰를 통한 품질을 검토한다.
1. 체크리스트 기반의 이해관계자 리뷰를 수행한다.
각 모델링 단계(개념 데이터 모델링, 논리 데이터 모델링, 물리 데이터 모델링 등)의
모델러를 비롯한 이해관계자의 품질 검토를 수행한다.
2. 물리 데이터베이스 모델 품질 검토 보고서를 작성한다.
모델러와 이해관계자가 작성한 체크리스트의 내용을 종합하여 물리 데이터베이스 모
델 품질 검토 보고서를 작성한다.

76
<표 5-1> 데이터 품질 체크리스트 예시
대상
검토항목
검토 내용
평가
Low ~ High
Point 0 ~ 5
비고
Point
내용별
총
테이블
명명
- 명명 규칙을 준수하였는가?
- 제한요건에 따라 약어를 사용한 경우 약어사용 규칙을 준수하였는가?
- 의미 전달이 명확한 명칭을 사용하였는가?
- 테이블 한글명은 엔터티 명칭과 일치하는가?
설명
- 데이터 집합의 개요나 성격, 관리 목적 등을 설명하였는가?
- 데이터 집합 구성상의 특징이 설명되어 있는가?
- 데이터 집합의 생명 주기나 오너쉽 등을 비롯한 기타 특이 사항에 대
한 내용을 포함하고 있는가?
- 설명된 내용은 모든 이해관계자가 이해하고 의사소통 하는 데에 어려
움이 없도록 쉽고 상세하게 기술되었는가?
정의
- 특별한 이유가 존재하지 않는한 논리 데이터 모델의 엔터티가 누락없
이 물 리 데이터 모델로 변환되었는가?
- 테이블 형태는 성능을 고려하여 결정되었는가? (일반 힙 테이블, IOT,
클 러스터, 클러스터드 테이블, 파티션 등)
- 서브 타입의 변환 형태는 명확한 판단 기준에 의해 결정되었는가?
- 테이블 생성 관련 파라미터들은 적절하고 충분하게 정의되었는가?
- 향후의 업무 변화 가능성에 대비하여 모델 변경을 최소화할 수 있도록
유연 성, 확장성이 고려되었는가?
통합 수준
- 다른 영역에서 동일 목적으로 사용되는 테이블은 동일 명칭과 구조로
일관되게 사용되었는가?
권한
- 메타데이터 권한을 정의 하였는가? (테이블 생성/변경/삭제)
- 데이터 오너쉽을 정의 하였는가? (데이터 생성/변경/삭제)
- 테이블에 대한 접근 권한을 정의하였는가?
- 테이블에 대한 접근 권한은 적절하게 정의되었는가?
발생 건수/
빈도
- 현재의 데이터 저장 건수/빈도는 파악하였는가?
- 향후 예상되는 데이터 저장 건수/빈도의 변화가능성은 파악하였는가?
법규
- 관련 법규에서 요구하는 데이터를 보관하기 위한 테이블을 정의하였는가?
- 조직 특성에 비추어 보호가 요구되는 테이블을 식별하였는가?
요구/
추적가능성
- 정의된 테이블은 요구 사항과 매핑이 되었는가?
칼럼
명명
- 칼럼명은 명명 규칙을 준수하였는가?
- 제한요건에 따라 약어를 사용한 경우 약어사용 규칙을 준수하였는가?
- 의미 전달이 명확한 명칭을 사용하였는가?
- 칼럼의 한글명은 속성명과 일치하는가?
정의
- 시스템 내부적으로만 사용되는 칼럼(입력자, 입력일시, 변경자, 변경일
시, 내부적으로만 사용되는 identity 칼럼 등) 외에 논리 모델 상에 정의
된 속성과의 얼라인먼트가 유지되고 있는가?
- 논리 모델의 인조식별자와 같이 일련번호를 저장하는 칼럼의 일련번호
생성 규칙과 방법이 정의되었는가? (Identity 칼럼, Sequence 객체 등)
설명
- 논리 모델에 정의된 속성의 개요나 성격, 관리 목적, 저장 데이터의 형
태적 또는 구성상의 특징 등이 물리 모델에 적합한 설명으로 작성되었
는가?
- 데이터 집합으로서 속성의 생명 주기나 오너쉽 등을 비롯한 기타 특이
사항에 대한 내용을 포함하고 있는가?
- 설명된 내용은 모든 이해관계자가 이해하고 의사소통 하는 데에 어려
움이 없도록 쉽고 상세하게 기술되었는가?
Primary Key
- PK 칼럼의 구성은 데이터의 유일성을 보장하기에 충분한가?
- FK 칼럼에 대한 참조무결성 규칙은 정의되었는가?
Unique Key
- PK 외에 본질식별자에 해당하는 모든 칼럼에 UK가 정의되었는가?
- 대체식별자로 정의된 칼럼에 대해 UK가 정의되었는가?

77
수행 tip
Ÿ
데이터 및 각각의 모델링 단계의 품질 기준이나 체크
리스트 등은 일관성은 있으나 각각의 특성을 반영하
여 다르게 나타난다.
Ÿ
아키텍처 등 상위 개념의 정책이나 품질 기준을 절대
적으로 적용하기보다 성능과, 오류 방지라는 물리 데
이터 모델 품질 검토의 목적을 감안하여 유연성 있게
대처해야 한다.
Ÿ
데이터 베이스 모델의 품질 검토는 반드시 각각의 단
계 모델러 및 이해관계자가 함께 참여해야 한다.
대상
검토항목
검토 내용
평가
Low ~ High
Point 0 ~ 5
비고
Point
내용별
총
법규 준수
- 법규상 암호화 대상인 칼럼의 데이터 타입과 길이는 암호화를 고려하
여 정의되었는가?
도메인 정의
- 표준 도메인을 정의하여 적용하였는가?
- 칼럼의 도메인(데이터 타입, 길이, Not Nul 제약, Default 제약, Check 제
약 등)은 일관성 있게 정의되었는가?
추출 칼럼의
정의
- 추출 칼럼에 대한 추출 방법 또는 산식이 명확하게 정의되었는가?
- 추출 칼럼에 대한 추출 방법 또는 산식을 적용한 방법은 적절한가? (어
플리케이션 로직, 트리거, 기타 등)
요구 사항
추적가능성
- 칼럼 수준에서 필요한 요구 사항 매핑은 수행되었는가?
오너쉽 정의
- 칼럼 수준에서 데이터 오너쉽 정의가 필요한 경우 데이터 오너쉽이 정
의되었는가?
FK
참조무결성
규칙 정의
- 논리 모델 상의 관계들은 특별한 이유가 없는한 누락없이 참조무결성
규칙이 정의되었는가?
- 정의된 참조무결성 규칙은 업무 영역의 내용이나 요구 사항과 일치하
는가?
- 배타적 관계의 FK 칼럼에 대한 참조무결성 규칙을 적용하기 위한 방법
은 적절한가? (DBMS의 FK 제약 조건, 어플리케이션 로직, DB트리거 등)
요구 사항
추적가능성
- 참조무결성 규칙에 대해 필요한 요구 사항 매핑은 수행되었는가?
FK 일관성
- FK 칼럼은 참조하는 PK 칼럼과 도메인 정의가 일치하는가?
모델전반
반정규화
- 반정규화 방법과 형태, 적용 범위는 적절한가?
- 반정규화된 테이블이나 칼럼은 명확한 목적에 근거하고 있는가?
인덱스
정의
- PK 인덱스 외에 추가적인 인덱스가 고려되었는가?
- PK 인덱스를 포함하여 인덱스의 구성 칼럼들은 절적하게 선정되었는
가?(액세스 경로 분석 수행 여부)
- 인덱스 생성에 관련된 파라미터들은 충분하고 적절하게 정의되었는가?
스토리지
정의
- 스토리지 구성은 I/O 분산과 액세스 성능을 고려하여 정의했는가?
- 스토리지 정의 파라미터들은 적절하게 정의되었는가?
- 테이블과 인덱스는 적절한 테이블스페이스에 할당되었는가?
출처: 데이터 품질 관리 지침 참조, 한국데이터베이스 진흥원, 2006
78
학습 5
교수 ‧ 학습 방법
교수 방법
• 데이터 아키텍처 정책, 데이터 표준화, 데이터 품질 정책, 데이터 품질 기준 등에 대한 학습자의
사전 이해 정도를 확인한다.
• 데이터 아키텍처 정책, 데이터 표준화, 데이터 품질 정책, 데이터 품질 기준, 데이터 모델 품질
검토 체크리스트 등의 자료가 갖춰졌는가를 확인하고 제공할 수 있어야 한다.
• 논리 모델링의 결과 즉 산출물이 확보되어 있다면, 본 물리 모델의 교육 내용과 관련 사항을
리스트화 하여, 반드시 학습자에 설명한다.
• 교수자는 효과적인 학습을 위해 ‘데이터 품질 관리’학습모듈과 연계하여 설명한다.
• 교수자는 기술적인 부분도 중요하지만 품질 검토의 목적과 수행의 유연성을 염두에 두고 강의
한다.
• 교육상에 발생하는 산출물은 대부분 학습자가 사용하는 데이터베이스나 학습자가 속한 조직
및 업무에 따라 상이하게 달라질 수 있다. 따라서 형식보다 산출물에 포함되는 내용의 의미와
역할 등을 중심으로 설명한다.
학습 방법
• 데이터 표준화, 품질 정책, 품질 기준 등에 대해 이해한다.
• 물리 데이터 모델의 품질 검토라는 특성을 충분히 고려한다.
• 물리 데이터 모델 품질 검토의 목적에 대해 이해한다.
• 물리 데이터 모델 품질 체크리스트의 체크 항목과 내용에 대해 이해한다.
• 학습자는 교육내용상 제시되는 산출물이나 참고 자료의 형태가 본인이 주로 사용하는 데이터베
이스 프로그램이나 소속된 조직의 업무 양식과 다를 수 있음을 인지하고 형식보다 포함된 속성의
의미와 필요성을 이해해야 한다.

79
학습 5
평 가
평가 준거
• 평가자는 피평가자가 수행 준거 및 평가 내용에 제시되어 있는 내용을 성공적으로 수행할 수
있는지를 평가해야 한다.
• 평가자는 다음 사항을 평가해야 한다.
학습 내용
평가 항목
성취수준
상
중
하
물리 데이터 모
델 품질 점검
- 물리 데이터 모델에 대하여 정확성, 완전성, 준거성,
최신성, 일관성, 활용성의 품질 기준을 적용할 수 있다.
- 논리 데이터 모델과 물리 데이터 모델을 비교하여
테이블, 칼럼, 키, 오브젝트 구성 요소의 누락 여부
와 일치성을 확인할 수 있다.
- 물리 데이터 모델의 품질 기준에 따라 테이블, 칼럼,
키에 대하여 데이터 표준화 준수 여부를 확인하고
품질 검토 보고서를 작성할 수 있다.
평가 방법
• 서술형 시험
학습 내용
평가 항목
성취수준
상
중
하
물리 데이터 모
델 품질 점검
- 물리 데이터 모델에 대하여 정확성, 완전성, 준거성,
최신성, 일관성, 활용성의 품질 기준의 적용을 이해
하는 가를 평가.
- 논리 데이터 모델과 물리 데이터 모델을 비교하여 테
이블, 칼럼, 키, 오브젝트 구성 요소의 누락 여부와
일치성 등의 특성과 차이점을 이해하는 가를 평가.
- 물리 데이터 모델의 품질 기준에 따라 테이블, 칼럼,
키에 대하여 데이터 표준화 준수 여부를 확인하고
품질 검토 수행에 대해 이해하는 가를 평가.
• 포트폴리오
학습 내용
평가 항목
성취수준
상
중
하
물리 데이터 모
델 품질 점검
- 물리 데이터베이스 모델 품질 검토 기준 및 테이블,
칼럼, 키에 대하여 데이터 표준화 준수 여부등 품질
기준에 대한 체크리스트를 작성하고 활용할 수 있는
가를 평가

80
• 평가자 체크리스트
학습 내용
평가 항목
성취수준
상
중
하
물리 데이터 모
델 품질 점검
- 물리 데이터 모델에 대하여 정확성, 완전성, 준거성,
최신성, 일관성, 활용성의 품질 기준을 이해하는 가
를 평가
- 논리 데이터 모델과 물리 데이터 모델을 비교하여
테이블, 칼럼, 키, 오브젝트 구성 요소의 누락 여부
와 일치성 등의 특성과 차이점을 이해하는가를 평가
- 물리 데이터베이스 모델 품질 검토 기준 및 테이블,
칼럼, 키에 대하여 데이터 표준화 준수 여부 등 품
질 기준에 대해 검토하는 체크리스트의 내용에 대해
이해하는 가를 평가
피 드 백
1. 서술형 시험
- 물리 데이터 모델에 대하여 품질 기준의 적용을 이해하는가를 확인하여 부족한 부분을
숙지하도록 한다.
- 논리 데이터 모델과 물리 데이터 모델을 비교하여 특성과 차이점을 이해하는가를 확인하
여 부족한 부분을 숙지하도록 한다.
- 물리 데이터 모델의 품질 기준에 대한 품질 검토 수행 과정을 이해하는 가를 확인하여
부족한 부분을 숙지하도록 한다.
2. 작업 포트폴리오
- 물리 데이터베이스 모델 품질 검토 기준 및 테이블, 칼럼, 키에 대하여 데이터 표준화 준
수 여부등 품질 기준에 대한 체크리스트를 작성하고 활용할 수 있는 가를 확인한다.
3. 체크리스트를 통한 관찰
- 물리 데이터 모델에 대하여 품질 기준의 적용을 이해하고 있는가를 확인하여 부족한 부
분을 보충하도록 한다.
- 논리 데이터 모델과 물리 데이터 모델을 비교하여 특성과 차이점을 이해하고 있는가를
확인하여 부족한 부분을 보충하도록 한다.
- 물리 데이터 모델의 품질 기준에 대한 품질 검토 수행 과정을 이해하고 있는가를 확인하
여 부족한 부분을 보충하도록 한다.

81
∙ 이종균 외 6명(2006). 「The Guide for Data Architecture Professional, 데이터아키텍처 전문가
가이드」, 한국데이터베이스 진흥원
∙ 이춘식(2005). 「데이터베이스 설계와 구축」, 한빛미디어
∙ 한국데이터베이스 진흥원(2006). 「데이터 품질 관리 지침」, 한국데이터베이스 진흥원
∙ 한국데이터베이스진흥원, http://www.dbguide.net/, DB 구축가이드


NCS학습모듈 개발이력
발행일
2015년 12월 31일
세분류명
DB엔지니어링(20010204)
개발기관
한국소프트웨어기술진흥협회, 한국직업능력개발원
집필진
편흥열(에이비엔아이)*
검토진
김보운(이화여자대학교)
강성구(명지대학교)
여권동(NDS시스템)
김승현(경희대학교)
정금묵(베이스존)
박미화(투이컨설팅)
주선태(T3Q)
박준자(한국오라클)
진권기(이비스톰)
임영섭(비투엔컨설팅)
장온순(한국IT컨설팅)
장인혁(청운)
*표시는 대표집필자임
발행일
2018년 12월 31일
학습모듈명
물리 데이터베이스 설계(LM2001020404_16v3)
개발기관
한국직업능력개발원
물리 데이터베이스 설계(LM2001020404_16v3)
저작권자
교육부
연구기관
한국직업능력개발원
발행일
2018.12.31
※
이 학 습 모 듈 은 자 격 기 본 법 시 행 령 (제 8조 국 가 직 무 능 력 표 준 의 활 용 )에 의 거 하 여 개 발
하 였 으 며 , NCS통합포털사이트(http://www.ncs.go.kr)에서 다운로드 할 수 있습니다.

